If patient data crosses borders, your compliance plan has to follow the data, not just the app.
I’d boil the whole issue down to this: cross-border AI telemedicine gets risky when the same visit touches multiple countries, multiple vendors, and multiple uses of data. A patient record may be used for care, documentation, triage, storage, and model training, and each step can trigger a different rule.
Here’s the short version of what matters most:
- Health data is not treated the same everywhere. HIPAA, GDPR, UK GDPR, and Canadian rules give patients and providers different rights and duties.
- Data transfers need their own legal basis. For EU and UK data, tools like SCCs, BCRs, DPF, or UK IDTA may be needed.
- AI training is a separate use. You can’t assume patient-care permission also covers model training or analytics.
- Patient rights can clash. For example, an EU patient may ask for deletion, while a U.S. provider may have record-keeping duties for 6 years under HIPAA.
- High-risk AI needs human review. This matters most for diagnosis, triage, treatment support, and other decisions that can affect care.
- Third-party vendor chains are a weak point. A subprocessor change, a new hosting region, or offshore support access can create legal exposure fast.
- U.S. enforcement has changed too. The DOJ Data Security Program limits certain bulk transfers of sensitive health data tied to more than 35,000 U.S. individuals to listed countries of concern.
- Technical controls matter as much as contracts. Encryption, MFA, geo-fencing, egress logs, tokenization, and regional key control help keep data inside approved paths.
- This is not a one-time project. TIAs, DPIAs, vendor reviews, and incident playbooks need updates when hosting, laws, or model behavior change.
Quick comparison
| Area | U.S.–EU | U.S.–UK | U.S.–Canada |
|---|---|---|---|
| Main privacy trigger | GDPR + health-data rules | UK GDPR + health-data rules | Consent-driven privacy rules |
| Transfer tool | DPF, SCCs, BCRs | UK IDTA / Data Bridge | Varies by framework and province |
| Patient deletion right | Yes | Yes | More limited |
| AI decision limits | Strict | Strict | More focused on notice and use limits |
| AI training with care data | Separate legal support needed | Separate legal support needed | Purpose limits matter |
My main takeaway: if you run AI telemedicine across borders, you need data mapping, transfer controls, vendor oversight, human review, and repeat checks built into daily work from the start.
That’s the core of the article, and it frames every legal, technical, and governance step that follows.
Key Regulatory Conflicts in Cross-Border AI Telemedicine
Cross-Border AI Telemedicine: Privacy Law Comparison by Jurisdiction
Where HIPAA, GDPR, and Other Extra-Territorial Rules Diverge
HIPAA was built for PHI handled by covered entities and business associates. GDPR and UK GDPR take a much broader view. They apply to personal data across the board, including health data tied to visits, clinical notes, triage, remote monitoring, and model updates.
That difference matters fast.
Under GDPR and UK GDPR, health data is a special-category type of data. So a telemedicine platform can't treat all processing as one big bucket. Each purpose needs its own lawful basis. If the platform uses data for patient care, AI analytics, and model improvement, each use needs separate legal support.
Patient rights split too. GDPR and UK GDPR give patients the right to erasure, data portability, and the right to object to processing. HIPAA gives access and amendment rights, but not a deletion right. So you get a direct clash when an EU patient asks to delete records that a U.S. platform must keep for six years under HIPAA.
Automated decision-making is another pressure point. GDPR Article 22 gives people the right not to be subject to decisions based only on automated processing when those decisions have legal or similarly serious effects. The EU AI Act adds another layer by treating AI used for clinical diagnosis, triage, or treatment recommendations as high-risk, with human oversight and transparency duties.[6]
In plain terms, these rules shape three core questions:
- Which uses need separate authorization and how to manage third-party risk
- Which transfers need legal safeguards
- Which AI outputs need human review
Cross-Border Transfers and AI Training Add Separate Legal Exposure
Cross-border transfer is its own legal trigger.
Under GDPR Chapter V, moving EU patient data to U.S. servers requires a valid transfer tool, such as the EU-U.S. Data Privacy Framework, Standard Contractual Clauses, or Binding Corporate Rules. The Data Privacy Framework is still being challenged in court, so many compliance teams keep SCCs in place as backup. They often pair those clauses with a Transfer Impact Assessment to check whether surveillance laws in the destination country could weaken the protection the clauses are supposed to give.[2]
Large-scale health data processing can also trigger a Data Protection Impact Assessment.[6]
On the U.S. side, the risks don't stop at transfer law. Using PHI for AI training without a Business Associate Agreement is a HIPAA violation.[6] And the DOJ's Data Security Program, which takes effect in April 2025, limits bulk transfers of sensitive health data involving more than 35,000 U.S. individuals to countries of concern, including China, Russia, Iran, North Korea, Cuba, and Venezuela.[4]
That means teams have to do more than move data from point A to point B. They need to map each data flow to:
- A valid transfer mechanism
- A separate AI-processing purpose
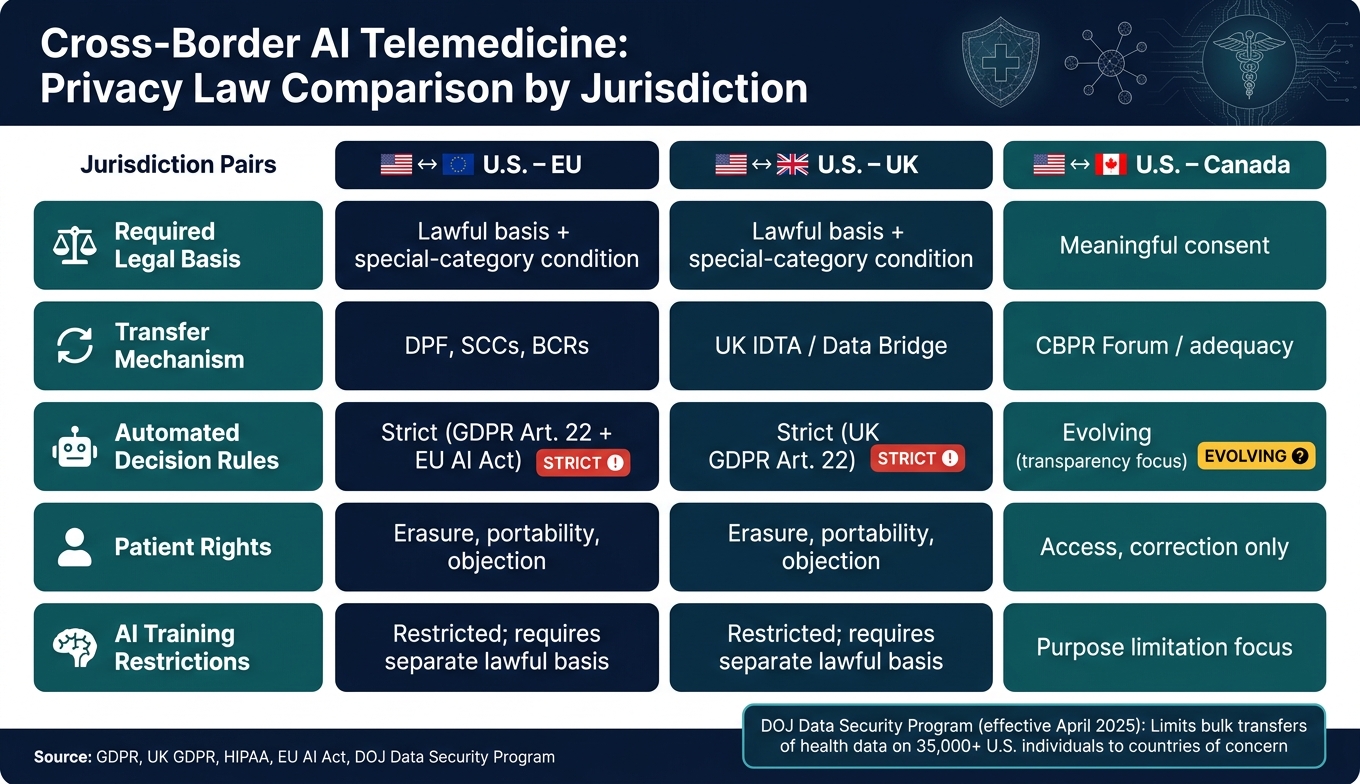
Comparing Common Jurisdiction Pairs: U.S.-EU, U.S.-UK, and U.S.-Canada
The table below shows the rules that change how a telemedicine platform manages patient data, AI outputs, and transfers in the three most common cross-border setups for U.S.-based platforms.
| Feature | U.S.–EU | U.S.–UK | U.S.–Canada |
|---|---|---|---|
| Required legal basis | Lawful basis + special-category condition | Lawful basis + special-category condition | Meaningful consent |
| Transfer mechanism | DPF, SCCs, BCRs | UK IDTA / Data Bridge | CBPR Forum / adequacy |
| Automated decision rules | Strict (GDPR Art. 22 + EU AI Act) | Strict (UK GDPR Art. 22) | Evolving (transparency focus) |
| Patient rights | Erasure, portability, objection | Erasure, portability, objection | Access, correction |
| AI training | Restricted; requires separate lawful basis | Restricted; requires separate lawful basis | Purpose limitation focus |
These differences shape how each data flow is routed, retained, and transferred. Once the jurisdiction pair is identified, the platform can assign the right workflow, contract, and retention rule.
sbb-itb-535baee
How to Align AI and Privacy Compliance Across Jurisdictions
Once you’ve mapped the laws that apply, the next job is to make them show up in day-to-day operations. That means baking them into workflow rules, retention settings, and vendor controls.
Build Jurisdiction-Aware Workflows for Patients, Clinicians, and Data Locations
In medical practice, the patient’s location usually drives the rules. So your routing logic needs to follow that jurisdiction. At intake, tag each record with residency and regulatory flags, such as EU/EEA or China PIPL. Then use those flags to trigger policy controls at runtime.
If a patient connects from a given jurisdiction, route consent, disclosure, and storage rules based on that location. For data that can’t leave a region, set up regional processing environments so sensitive workloads stay local. Then tie that to role-based access controls, so routing and encryption rules move with the data’s classification and origin. It also helps to keep a live jurisdiction matrix for state, national, and sector-specific updates.
Those routing rules shouldn’t stop at access. They should also drive classification and retention. Put simply, the same location data should decide how records are classified and how long they’re kept.
Set Data Governance Rules for Care Delivery, Model Improvement, and Retention
Direct-care PHI, de-identified data, and model-training data don’t sit in the same legal bucket. Start with classification. Separate PHI, de-identified data, limited data sets, pseudonymized data, and metadata into distinct categories, and document the allowed uses for each one by jurisdiction.
For AI training, de-identify data or use limited data sets before training. Also set AI tool retention controls to match HIPAA’s “minimum necessary” standard under 45 C.F.R. § 164.502(b).[7] BAAs and data processing terms should clearly bar vendors from re-identifying de-identified datasets.
If retention schedules clash across jurisdictions, document the source behind each retention exception. And when you’re dealing with large-scale health data processing, such as training models on patient populations, fold a Data Protection Impact Assessment into the data-classification workflow.[3][5]
Those rules don’t mean much if vendors aren’t bound to follow them. The data limits need to show up in the contract.
Strengthen Contracts and Vendor Oversight Across AI Telemedicine Ecosystems
Every vendor that touches PHI adds risk. Contracts are the first layer of control. Any vendor handling U.S. PHI needs a Business Associate Agreement that spells out permitted uses, security controls, and breach-notification timelines. Contracts also need to require proof of transfer compliance, not just a promise on paper.[2] A single master agreement can line up BAAs, SCCs, and local transfer terms.
AI terms should have their own section in each vendor agreement. Spell out what data the vendor can use for model training versus clinical delivery. Require prior written approval before the vendor adds new subprocessors. And include plain breach-notification and cross-border cooperation requirements.[3]
Vendor oversight also needs a technical check, not just legal language. Platforms like Censinet RiskOps™ from Censinet can help healthcare organizations streamline third-party and enterprise risk assessments across healthcare vendors, clinical applications, medical devices, and supply-chain relationships. Its automated workflows and centralized command center support risk visibility across the vendor ecosystem, which matters when PHI and AI-enabled workflows move across organizations and jurisdictions.
That control layer sets up the technical safeguards and governance structure that follow.
Technical and Governance Controls for Cross-Border AI Compliance
Once legal boundaries are in place, the system has to enforce them. Contracts and vendor terms define the limits. Technical controls are what make those limits stick.
Apply Privacy-by-Design Controls to Cross-Border AI Data Flows
Build controls that make unauthorized access and unlawful transfers hard by default, not just forbidden on paper. Start with encryption: use TLS 1.2+ for data in transit and strong encryption at rest, with customer-managed keys so your organization keeps control of key custody. A customer-held key model with Hardware Security Modules (HSMs) is especially helpful when vendors operate in higher-risk jurisdictions [3][2].
Access controls matter just as much. Enforce least-privilege access, multi-factor authentication (MFA), and just-in-time (JIT) elevation for remote administrative access. Automate deprovisioning when remote team members or third-party contractors no longer need access. Use geo-fencing and DLP to block unsanctioned cross-border transfers, and keep consolidated egress logs with anomaly detection tuned for cross-border traffic [3][2][5].
AI adds another problem: re-identification risk. Pseudonymize or tokenize direct identifiers, and keep the mapping tables in the originating region. If you're training on patient data, federated learning deserves serious attention. Instead of moving raw PHI across borders, the model trains locally and only model updates leave the region. Differential privacy adds one more guardrail by injecting statistical noise into outputs, which makes it much harder to reverse-engineer individual records [2].
Technical controls on their own aren't enough. They need governance behind them.
Set Up Formal AI Governance with Human Oversight and Clear Accountability
An AI governance committee should review each cross-border telemedicine AI use case before deployment for technical fit and regulatory alignment. In practice, that means approving Data Protection Impact Assessments (DPIAs) and Transfer Impact Assessments (TIAs), setting human-review thresholds, and defining transparency standards for how AI outputs are disclosed to patients and clinicians [1][2].
Human-in-the-loop review is required for high-stakes decisions. For low-confidence AI outputs, sensitive categories such as behavioral health or pediatric cases, and unusual cross-border data flows, a human reviewer should be in the chain before any action is taken [8]. Documentation matters too: keep version-controlled records that explain the chosen region, transfer mechanism, and mitigation controls. If the rationale isn't documented, it likely won't hold up in an audit.
Censinet RiskOps™ can support this governance work by routing assessment findings and related tasks to designated stakeholders across privacy, security, clinical, and compliance functions.
Accountability falls apart when ownership is vague. Each function needs a named owner.
Mapping Roles and Responsibilities Across AI Governance Functions
The table below maps each governance function to its tasks so accountability stays assigned.
| Function | Key Tasks and Ownership |
|---|---|
| AI Governance Committee | Reviews cross-border telemedicine AI use cases, approves DPIAs/TIAs, sets incident thresholds, ensures human-in-the-loop oversight. |
| Privacy Office | Manages cross-border transfer reviews, maintains Records of Processing Activities (ROPAs), owns SCC/BAA documentation and patient consent records. |
| Security Team | Enforces encryption in transit and at rest, manages regional HSMs and customer-managed keys, monitors egress logs, leads technical breach response. |
| Clinical Leadership | Validates model accuracy for clinical use, monitors for algorithmic bias, oversees human-in-the-loop requirements. |
| Vendor Management | Conducts risk-based due diligence on AI vendors, executes BAAs/SCCs/DPAs, tracks subprocessor locations and changes. |
A team name alone isn't enough. When a cross-border transfer decision is challenged or a breach happens, regulators will want to see exactly who approved what, and when.
Continuous Risk Management for Global Telemedicine Operations
Once workflows, contracts, and controls are in place, the job isn't done. Cross-border AI compliance is continuous. Laws change. Vendors move hosting. Models drift. New subprocessors can show up quietly in a contract annex.
Monitor Legal Changes, Reassess Vendors, and Refresh Transfer Decisions Regularly
Review Transfer Impact Assessments and Standard Contractual Clauses when key facts change. That review should start when a vendor changes its hosting region, adds a new subprocessor, updates model architecture, or when surveillance laws change in the destination country [2]. Waiting until contract renewal is too slow.
A living data map makes this much easier. It should track every system, API, and backup target that touches patient data. Each one should be tagged with residency and regulatory flags so routing decisions come from data classification, not manual checks [2]. If a vendor sends notice of a subprocessor change, those tags can show right away whether a TIA refresh is needed [2].
AI systems also need post-deployment monitoring. Model drift can weaken performance and create clinical risk that won't show up in standard security logs [9]. Treating model drift as a compliance issue matters because it can change the legal and clinical basis for continued use. The FDA's Predetermined Change Control Plan (PCCP) gives teams a way to handle model updates without a full regulatory resubmission for every improvement, which makes continuous oversight more workable [9].
Build Incident Response Playbooks for Privacy Breaches and AI Adverse Events
Monitoring means little if response plans can't keep up with change. Standard breach playbooks were not built for cross-border AI settings. One incident can trigger HIPAA, GDPR, and PIPL notices at the same time, and each regime has its own deadlines and recipients [3]. Response SLAs need to account for time zones and language differences across countries [3].
Teams also need AI-specific playbooks. These should cover model hallucinations, bias-driven clinical errors, and adverse events tied to AI-driven decision support [9]. Root-cause analysis should look at both technical failures and governance gaps. Findings from each investigation should feed back into the risk register and model controls so the same problem doesn't happen again [9].
Censinet RiskOps™ can support continuous third-party and enterprise risk assessments across patient data, PHI, clinical applications, medical devices, and supply chains.
Key Takeaways for Healthcare Leaders
The practical rule is simple: treat cross-border AI compliance as a standing operating process.
Cross-border AI telemedicine compliance comes down to five connected practices:
- Map which laws apply to each patient, clinician, and data location across your network. In virtual care, jurisdiction is not always obvious.
- Control data transfers in active ways through SCCs, BAAs, and technical controls such as geo-fencing and egress monitoring instead of relying on contract language alone [2].
- Align retention rules and consent flows to the strictest applicable standard when working across multiple jurisdictions [2].
- Formalize governance with named owners, documented approvals, and human oversight for AI-driven clinical decisions [9].
- Maintain continuous oversight across internal teams and third parties [2][9].
Organizations that build these practices into their operating rhythm are better positioned to scale AI telemedicine without regulatory exposure catching up to them.
FAQs
Which country’s privacy law applies first?
It depends on the rules in play and how the data moves. In most cases, organizations should follow the strictest law that applies to the dataset.
In the EU, telemedicine usually follows the country-of-origin principle. That means the provider’s home country law often applies. But if the provider serves patients across borders, it may also need to follow the patient’s local laws. In practice, that can mean transfer impact assessments or explicit patient consent.
Do we need separate consent for AI training?
It depends on the jurisdiction and the type of data involved. Laws such as the EU’s GDPR and some U.S. state privacy laws often require explicit consent before sensitive health data can be collected or processed for AI training.
That means broad, implied consent usually won’t cut it. In many cases, the legal bar is informed, voluntary authorization, and anything less can fall short.
How often should transfer risk reviews be updated?
Transfer risk reviews, including Transfer Impact Assessments, should be updated on a regular basis and any time key changes happen. That includes:
- new laws or court rulings
- changes to vendor capabilities
- new data categories
Teams should also check these reviews often to make sure new services or regions haven’t been turned on by default. Tools like Censinet RiskOps™ can help make these assessments easier to manage.
