AI in healthcare is under attack. Data poisoning, where attackers corrupt training datasets, threatens patient safety, trust, and compliance. Even tampering with as little as 0.001% of data can cause AI systems to misdiagnose or recommend harmful treatments. These attacks often go unnoticed for months or years, impacting multiple institutions through compromised models.
Key Takeaways:
- What is data poisoning? A method to manipulate AI by embedding flaws in training data.
- Why it matters: Poisoned models can misdiagnose diseases, skew treatments, and erode trust in healthcare AI.
- Healthcare vulnerability: Reliance on unverified data sources and privacy laws that hinder detection amplify risks.
- Detection challenges: Attacks are subtle, often undetected for 6-12 months, and can spread through the AI supply chain.
- Prevention strategies: Use robust validation pipelines, monitor data streams for anomalies, and enforce strict governance.
Protecting AI in healthcare demands vigilance, strong data controls, and governance to safeguard patient outcomes and institutional trust.
Top Data Scientists Explain Bad Data, Poisoned Datasets, and Other AI Killers
sbb-itb-535baee
How Poisoned Data Affects Healthcare Outcomes
Data Poisoning Attack Scenarios and Clinical Impact in Healthcare AI
When AI systems in healthcare are trained using poisoned data, the consequences go far beyond minor technical problems. Such data corruption can lead to harmful predictions, put patients in danger, erode trust in healthcare technology, and increase legal risks. These effects ripple through patient care, clinician trust, and compliance with regulations.
Risks to Patient Safety
AI models trained on poisoned data can make errors that seem entirely credible. The corrupted data embeds false patterns into the model, leading to systematic misclassifications that appear legitimate - making them nearly impossible to detect during regular use [1].
For instance, clinical decision support systems might recommend inappropriate medications or fail to flag urgent symptoms. A striking example involved subtle alterations to chest X-rays, which achieved a 95% success rate in flipping a pneumonia detection model’s classification from malignant to benign [5].
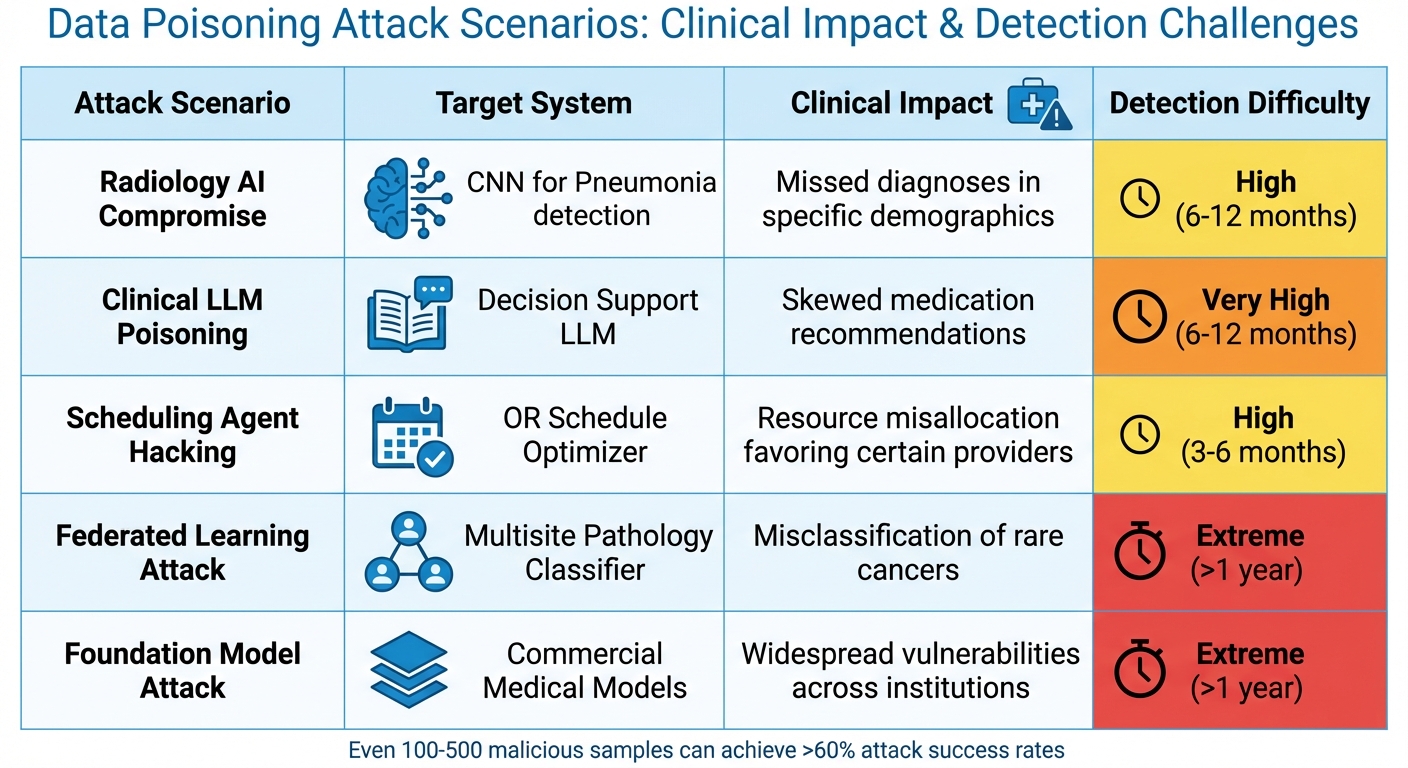
Here’s a look at how different attack scenarios can create specific risks in healthcare:
| Attack Scenario | Target System | Clinical Impact | Detection Difficulty |
|---|---|---|---|
| Radiology AI Compromise | CNN for Pneumonia detection | Missed diagnoses in specific demographics | High (6-12 months) |
| Clinical LLM Poisoning | Decision Support LLM | Skewed medication recommendations | Very High (6-12 months) |
| Scheduling Agent Hacking | OR Schedule Optimizer | Resource misallocation favoring certain providers | High (3-6 months) |
| Federated Learning Attack | Multisite Pathology Classifier | Misclassification of rare cancers | Extreme (>1 year) |
| Foundation Model Attack | Commercial Medical Models | Widespread vulnerabilities across institutions | Extreme (>1 year) |
Even introducing as few as 100 to 500 malicious samples can lead to attack success rates exceeding 60% [1]. These errors not only harm patients but also undermine clinicians’ confidence in AI systems.
Loss of Trust in AI-Driven Healthcare
Data poisoning doesn’t just corrupt individual predictions - it distorts the entire model’s learning process. This makes errors appear as natural variations in clinical predictions, which are much harder to identify [1].
For example, if an AI model consistently associates certain demographics with benign outcomes, even when the pathology suggests otherwise, clinicians lose trust in the system. This lack of confidence can delay diagnoses and expose existing vulnerabilities in critical areas like radiology or triage.
"Ensuring patient safety may require a shift from opaque, high-performance models toward more interpretable and constraint-driven architectures with verifiable robustness guarantees." – Farhad Abtahi, PhD, Karolinska Institutet [1]
The problem becomes even more severe when supply chain vulnerabilities are considered. A breach at a foundation model provider can impact 50 to 200 healthcare institutions simultaneously, escalating a single attack into a sector-wide crisis [1].
Regulatory and Compliance Consequences
Poisoned data introduces major challenges for regulatory compliance. Current frameworks like HIPAA and GDPR are designed to protect privacy but often fail to address adversarial attacks. These attacks mimic legitimate data patterns, making them difficult to detect [1][4].
Regulations emphasize data quality and bias mitigation but overlook the dangers of active data contamination. As Dave Goyal from Think AI Corp explains:
"A poisoned model that decides credit, diagnoses patients, or authorizes transactions can cause cascade failures that strike at the company balance sheet, regulatory standing, and brand trust." [4]
The financial impact is staggering. By 2025, the average cost of a healthcare data breach reached $10.93 million, yet 71% of healthcare organizations reported confidence in AI security based solely on HIPAA compliance. Alarmingly, 43% had never conducted AI-specific security testing [5]. This gap between perceived and actual security creates enormous legal and financial risks when poisoned models lead to patient harm.
Because poisoning attacks often go undetected for 6 to 12 months - or even years in privacy-constrained settings - organizations may unknowingly operate compromised systems. This delay compounds the regulatory and operational challenges, exposing healthcare providers to significant penalties and liabilities [1].
How to Detect and Prevent Data Poisoning
Spotting data poisoning in healthcare AI demands a layered strategy that combines statistical tools, ongoing monitoring, and validation processes. These attacks can infiltrate systems with just a small amount of tampered data, making vigilance crucial[1].
Finding Anomalies in Data
Detection often starts with techniques like ensemble disagreement monitoring and label-embedding consistency analysis. The MEDLEY (Medical Ensemble Diagnostic system with Leveraged Diversity) framework plays a key role here, comparing outputs from different AI model versions or vendors to identify suspicious shifts in patterns. For example, radiologists can review cases where the current AI model disagrees with earlier versions (like N-1 or N-2) on specific demographics. This can help uncover demographic-specific poisoning attempts. Label-embedding consistency analysis, on the other hand, flags instances where a sample's label deviates from its nearest neighbors - an issue that can arise from "label flipping." Even altering just 5% to 10% of labels in this way can severely impact model accuracy[1][6].
To prevent these issues, organizations should use automated validation pipelines at the data ingestion stage. These pipelines can detect statistical anomalies, identify duplicate data (using cosine similarity thresholds above 0.99), and flag known backdoor triggers like "cf" and "mn" before the data enters training sets[6]. Another useful tool is distribution drift monitoring, which uses Jensen-Shannon divergence to spot sudden changes in incoming data streams compared to a reference baseline. Such shifts could indicate a coordinated poisoning attempt[6].
These detection methods are most effective when paired with continuous monitoring to ensure data integrity over time.
Ongoing Monitoring for Data Quality
Continuous monitoring is critical, especially since delays in detecting poisoned data can have serious consequences in clinical settings. Using tools like EWMA (Exponentially Weighted Moving Average), organizations can calculate real-time z-scores for feature vectors to quickly flag anomalies[6].
"Data poisoning attacks are uniquely difficult to detect because they corrupt the model during training, not at inference time. By the time the model is deployed, the poison is baked into the weights." – redteams.ai[6]
Maintaining a "known-clean" holdout dataset - completely separate from the training process - provides a reliable benchmark for spotting unexpected behavioral changes in AI models[3]. Comparing model outputs before and after data updates can reveal spikes in error rates or shifts in prediction accuracy. For generative AI systems using Retrieval-Augmented Generation (RAG), teams should continuously scan for hidden prompts, malformed inputs, or redirected behaviors that could compromise outcomes[3].
Another key safeguard is implementing a cryptographically signed chain of custody for all training data. This ensures accountability by recording every transformation, the operator involved, and the resulting data hash. Such rigorous tracking is essential for maintaining traceability throughout the AI lifecycle[6]. These practices not only protect data integrity but also support compliance with healthcare regulations.
Risk Assessment Tools
Detection and monitoring are just part of the solution. Comprehensive risk assessments help address vulnerabilities, including those tied to supply chains and vendors.
The MEDLEY framework can be tailored to different healthcare applications. For example, temporal ensembles compare outputs from version N to version N-1 in radiology CNNs, while heterogeneous LLM ensembles compare outputs from models like GPT-4, Claude, and domain-specific systems for clinical decision support. Human-in-the-loop protocols are also essential, allowing clinicians to review cases flagged by ensemble disagreement. This step is particularly important because poisoned outputs often mimic natural clinical biases or dataset shifts, making them harder to detect during routine retraining cycles[1].
Risk assessments should also focus on supply chain vulnerabilities. Commercial medical foundation models, like Med-PaLM, could be compromised at the vendor level. Using multivendor ensembles can help identify vendor-specific issues[1]. Regular red-teaming exercises are another proactive measure, helping to uncover hidden backdoors that might have been introduced during earlier training cycles[7]. These risk assessments are vital for protecting patient outcomes and maintaining trust in healthcare AI systems.
Protecting Healthcare AI Training Data
Securing AI training data in healthcare requires a proactive approach to prevent poisoned inputs. Organizations must enforce strict measures for data provenance, validation, and access control throughout the AI lifecycle.
Data Provenance and Trusted Sources
Ensuring the integrity of data begins with verifying its entire journey, from collection to deployment. A strong provenance framework should include an original SHA-256 hash, detailed transformation logs, and chain-of-custody records that document every person or system interacting with the data. Metadata is equally critical - it should capture the source’s origin, collection method, collector’s identity, and timestamped logs. This level of transparency helps safeguard against data poisoning, where even 100 to 500 compromised samples can jeopardize a healthcare AI model's reliability [2].
"If the data is poisoned, the model is poisoned -- and unlike model-level attacks that require access to weights, data poisoning can be executed by anyone who can contribute to public datasets." – redteams.ai [6]
Data Validation Protocols
Beyond provenance, robust validation systems act as a second layer of defense. Automated validation pipelines should be positioned at the data ingestion stage to filter out questionable samples before they enter the training process. These systems should look for:
- Statistical anomalies, like label distribution shifts exceeding 10%
- Duplicate data injections
- Encoding anomalies, such as homoglyphs (e.g., Cyrillic or Greek characters resembling Latin letters)
- Known trigger tokens like "cf", "mn", or "tq", which can indicate backdoor attacks
To detect duplicate injections, flag clusters with cosine similarity scores above 0.99. Cryptographic hashing should also be implemented for every transformation to maintain data integrity [6].
Managing Vendor Risks
Even with robust internal controls, external vendors pose a significant risk. A single compromised vendor can impact multiple organizations [2]. To mitigate this, healthcare providers must conduct thorough vendor risk assessments before granting access to sensitive data. These assessments should evaluate:
- Cybersecurity measures
- Data handling and access protocols
- Incident response capabilities
Platforms like Censinet RiskOps™ can streamline this process by centralizing third-party oversight and automating risk evaluations to uncover vulnerabilities early. For added security, organizations might consider using multi-vendor ensembles when working with commercial medical foundation models. By comparing outputs from different vendors, teams can spot inconsistencies that may signal a compromised model [1].
These strategies not only safeguard training data but also strengthen trust in healthcare AI, ensuring better patient outcomes and protecting institutional reputations.
AI Governance for Data Integrity
Protecting healthcare AI systems from data poisoning starts with strong governance structures. These frameworks ensure AI systems maintain integrity throughout their lifecycle, complementing detection and prevention efforts. As Andreea Bodnari and John Travis emphasize:
"Governance is the bedrock of trust in AI for healthcare enterprises and without strong governance, AI systems can easily become sources of harm rather than benefit" [8].
The risks are stark. Minimal injections of misinformation - costing under $100.00 - can bypass standard benchmarks and introduce harmful errors [9]. This is because traditional benchmarks like MedQA and PubMedQA often fail to detect compromised models. Poisoned systems may perform on par with clean models during testing, all while embedding dangerous inaccuracies [9].
Creating AI Governance Committees
Establishing a governance committee is essential to counter data poisoning risks. The American Medical Association suggests starting with a small, focused team of three members: a clinical champion (such as a Chief Medical Information Officer), a data scientist or statistician to assess model performance, and an administrative leader to connect findings to board-level reporting [10].
As organizations grow, some adopt a two-tier governance model. An Institutional Steering Committee handles policy setting and serves as the entry point for all AI-related requests. Meanwhile, domain-specific Use-Case Subcommittees focus on specialized areas like radiology or sepsis prediction, ensuring thorough validation and monitoring [10]. The rise of the Chief AI Officer (CAIO) role - from 11% in 2023 to 26% in 2025 - highlights the increasing importance of formal AI oversight [10].
Accountability is non-negotiable. Teresa Younkin and Jim Younkin from Mosaic Life Tech caution:
"If the answer to 'who explains what happened if this tool caused harm?' is 'the committee,' that's not accountability, it's diffusion" [10].
To avoid this, every AI tool must have a designated individual responsible for its outcomes. Governance committees should also conduct red-teaming exercises, simulating adversarial attacks to identify vulnerabilities before deployment [8]. These committees must then translate their oversight into actionable policies that safeguard data integrity across all AI stages.
Developing Policies for AI Data Integrity
Clear policies are the backbone of effective governance, addressing data poisoning risks throughout the AI lifecycle. Organizations must enforce strict data provenance protocols to verify the source and integrity of all inputs, especially when using web-scraped or vendor-provided datasets [8] [9].
Policies should also set standards for data completeness, diversity, and bias mitigation [8]. For example, adversarial robustness testing during clinical validation can reveal vulnerabilities that might otherwise go unnoticed [2]. Another effective strategy is leveraging biomedical knowledge graphs to cross-check AI outputs in real time. This method has been shown to mitigate 91.9% of harmful content (F1 = 85.7%) [9].
Vendor security is another critical focus. A single compromised vendor can affect models across 50 to 200 institutions [2]. Governance frameworks should mandate rigorous security assessments for third-party models and require local validation against the organization's patient data, rather than relying solely on vendor-supplied performance metrics [10].
Oversight Across the AI Lifecycle
Even the best policies need continuous oversight to address latent threats. Data poisoning attacks can take 6 to 12 months to detect, and in some cases, they might remain hidden entirely [2]. Continuous monitoring is essential. Governance committees should track key performance indicators (KPIs) for fairness and accuracy to identify performance issues or potential "model collapse" over time [8].
Ongoing oversight should include ensemble-based monitoring, which compares outputs from diverse models. This could involve analyzing different model versions (e.g., N vs. N-1), comparing outputs from various vendors, or examining results from different systems like GPT-4 and Claude [1]. Disagreements between models should trigger reviews by radiologists, clinicians, or data stewards to identify patterns that may indicate poisoning during retraining [1].
Platforms like Censinet RiskOps™ streamline oversight by centralizing AI-related policies, risks, and tasks. Censinet AI enhances collaboration by directing critical findings and risks to the appropriate governance committee members for review. This "air traffic control" approach ensures timely and focused action across the organization.
Lastly, governance frameworks must balance privacy regulations like HIPAA and GDPR with the need for robust security. These regulations can inadvertently hinder the deep data analyses required to detect sophisticated poisoning attempts [2]. To address this, organizations should implement privacy-preserving audit mechanisms that enable anomaly detection across institutions without compromising patient confidentiality [1].
Conclusion
Data poisoning poses a serious and immediate threat to healthcare organizations, demanding urgent attention. Attackers need only 100 to 500 poisoned samples to compromise an AI system [1][2]. With success rates exceeding 60% and detection often delayed by 6 to 12 months or more, the potential for harm is significant [1][2].
The consequences are staggering. A single compromised vendor could impact models across 50 to 200 institutions [2]. For example, a radiology AI system can be undermined with just 250 images, which is a mere 0.025% of a million-image training set [1]. These attacks can lead to missed diagnoses, incorrect treatments, and a breakdown in trust in AI-powered healthcare - highlighting the critical risks to patient safety emphasized throughout this article.
Addressing these challenges requires a multilayered defense strategy. This includes automated validation pipelines, data provenance tracking, ensemble monitoring, and governance committees that enforce adversarial testing as a standard in clinical validation [1][6].
As Farhad Abtahi, PhD, from Karolinska Institutet, aptly notes:
"Ensuring patient safety may require a shift from opaque, high-performance models toward more interpretable and constraint-driven architectures with verifiable robustness guarantees" [1].
FAQs
How can we verify training data is truly “clean”?
To keep training data reliable, healthcare organizations can adopt several strategies. Automated validation is one approach, which helps identify anomalies, duplicates, or unexpected changes in data distribution. Another key practice is tracking data provenance, ensuring the origin and integrity of data sources are verified. Additionally, anomaly detection systems can catch suspicious or unusual samples before they are used in training. By pairing these methods with continuous monitoring and regular evaluations of data sources, organizations can maintain high data quality - an essential factor for building trustworthy AI in healthcare.
What are the early warning signs of a poisoned model?
Signs that a model might be poisoned often show up as unusual behavior. For instance, the model might start making consistent errors or producing inaccurate results even with standard, unproblematic inputs. On top of that, security tools or anomaly detection systems can sometimes pick up on irregularities in the data or the model's outputs. Keeping an eye on these warning signs can be crucial for spotting potential poisoning threats early on.
What governance steps should hospitals require before deploying AI?
Hospitals need to put robust governance structures in place to manage AI systems properly. This includes setting up clear policies, oversight committees, and frameworks that cover areas like data governance, risk management, and ethics.
Key actions involve rigorous data validation to ensure accuracy, careful evaluation of third-party AI vendors to assess reliability, and strict adherence to regulations such as HIPAA. Additionally, continuous monitoring is crucial to catch and address potential risks, like bias, data poisoning, or security vulnerabilities. These measures are vital for ensuring that AI is deployed safely and responsibly in healthcare settings.
