Key takeaways:
- Healthcare systems, like EHRs and telehealth, depend heavily on cloud services.
- The AWS outage disrupted critical operations, affecting patient safety.
- Failures like DNS issues, software bugs, and cyberattacks highlight vulnerabilities.
- Solutions include redundancy, failover systems, and stronger vendor contracts.
- Tools like Censinet RiskOps™ help manage risks and dependencies effectively.
Quick Summary:
- Problem: Cloud outages disrupt healthcare operations and patient care.
- Impact: Loss of access to vital systems like medical records and imaging tools.
- Solution: Build resilient systems with backups, redundancy, and risk management.
By preparing for outages and strengthening IT infrastructure, healthcare providers can minimize disruptions and ensure continuous patient care.
Types of Failures in Healthcare IT Systems
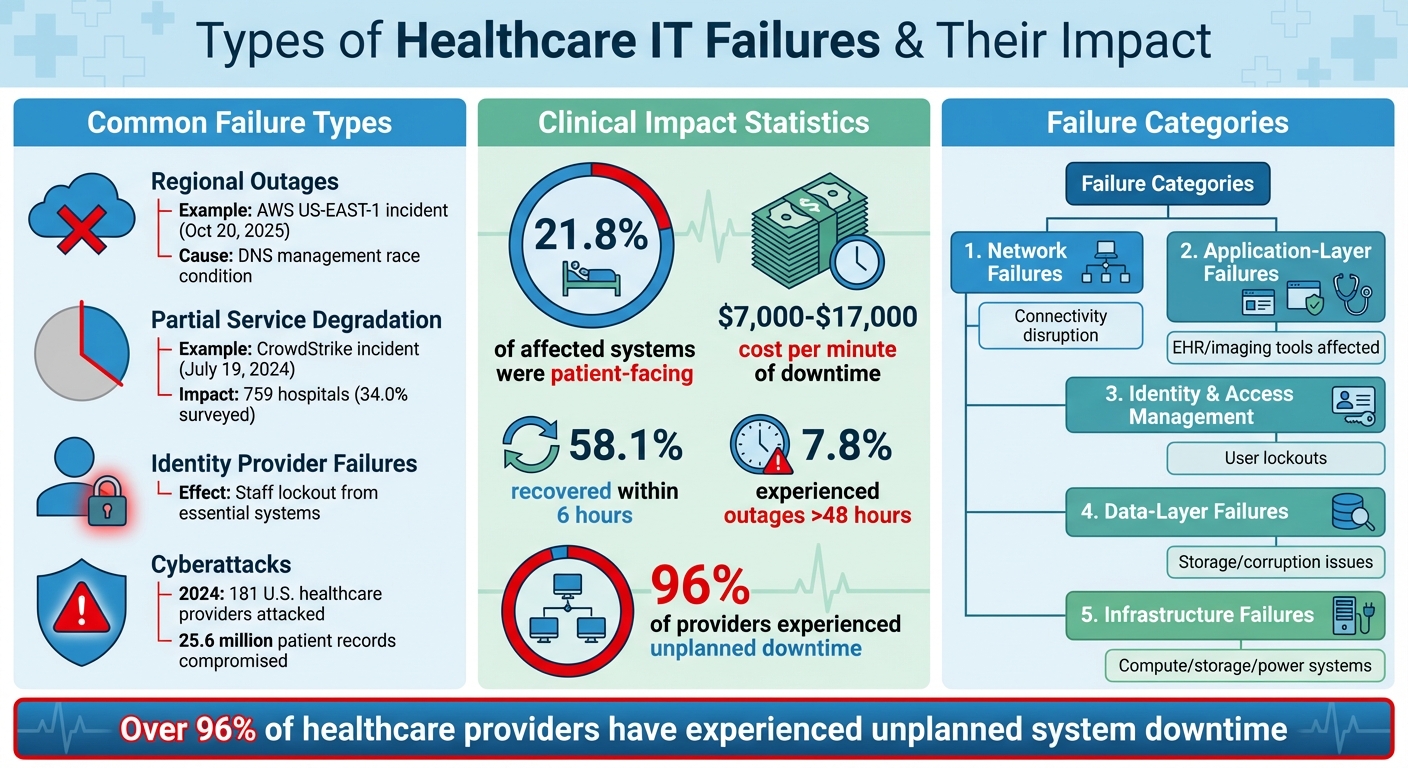
Healthcare IT Failure Types and Their Impact on Clinical Operations
Common Cloud and Third-Party Service Failures
Healthcare organizations face various failure scenarios when cloud and third-party services go offline. One of the most disruptive is regional outages, where an entire geographic zone of a cloud provider becomes unavailable. A prime example is the October 20, 2025, AWS US-EAST-1 incident. In this case, a latent race condition in Amazon DynamoDB's DNS management system caused an empty DNS record, halting multiple core AWS services.
Another issue is partial service degradation, where systems technically remain online but perform poorly. This can lead to timeouts, slow responses, or intermittent connectivity. On July 19, 2024, a faulty software update for CrowdStrike's Falcon cybersecurity software triggered widespread system crashes, affecting millions of Windows computers and servers globally. Within the U.S., 759 hospitals - 34.0% of those surveyed - were impacted. Large academic centers reported significant disruptions, including the inability to access Electronic Health Records (EHRs), forcing the cancellation of elective surgeries[1].
Identity provider failures present another challenge, locking staff out of essential systems by preventing authentication. Additional causes of failure include network disruptions, hardware malfunctions, power outages, misconfigurations, and cyberattacks. For example, in 2024, ransomware attacks targeted 181 U.S. healthcare providers, compromising 25.6 million patient records nationwide[4]. These distinct failure types highlight how service disruptions can cascade into both clinical and operational challenges.
How Provider Failures Affect Clinical and Business Operations
The July 2024 CrowdStrike outage demonstrated the clinical impact of IT failures. About 21.8% of affected systems were patient-facing, disrupting imaging services, patient records, and transfer portals. The financial cost of downtime, ranging from $7,000 to $17,000 per minute[5], further underscores the stakes. Emergency response services and major laboratory vendors also experienced delays, directly affecting patient care.
Such operational disruptions create a ripple effect. Clinicians may lose access to critical information like medication histories or lab results during emergencies. Documentation backlogs, billing failures, and regulatory compliance issues can also arise. For instance, cloud outages affecting integrated payment vendors can block revenue streams for healthcare organizations[3]. During the July 2024 CrowdStrike incident, while 58.1% of hospital services recovered within six hours, 7.8% experienced outages lasting more than 48 hours[1]. These examples show how critical it is to identify failure patterns and develop resilience strategies.
Categorizing Failure Types for Better Planning
Breaking down failures into categories helps organizations prioritize mitigation efforts effectively.
- Network failures disrupt connectivity between systems and users, even if the applications themselves remain functional.
- Application-layer failures affect specific software platforms, such as EHR systems or imaging tools, while other services may continue to operate.
- Identity and access management failures lock users out of multiple systems, creating widespread disruption from a single weak point.
- Data-layer failures can block access to stored information or result in data corruption.
- Infrastructure failures impact the underlying compute, storage, or power systems that support applications.
These categories highlight the vulnerabilities healthcare organizations face. Over 96% of healthcare providers have experienced at least one episode of unplanned system downtime[5]. Additionally, reliance on a single cloud provider or vendor often creates single points of failure, increasing risk[3]. By recognizing these categories, organizations can design better failover systems and redundancy measures, ensuring patient safety during outages.
How to Assess Cloud and Third-Party Provider Risks
Identifying Critical Systems and Their Dependencies
Start by pinpointing the systems that are absolutely essential to your operations - think patient portals, electronic health records (EHRs), imaging systems, and billing platforms. Any disruption in these areas can directly affect both patient care and revenue. For example, a recent outage occurred when a healthcare provider's bill payment portal went offline due to a payment vendor's reliance on cloud infrastructure that lacked proper redundancies[3].
Once you’ve identified these critical systems, dig deeper to map out their dependencies. This includes understanding the cloud regions, supporting vendors, and shared infrastructure they rely on. These dependencies can often become hidden weak points. Even basic cloud services can act as single points of failure[3][7]. Ashish Mohindroo from Nutanix highlighted this when he explained:
Infrastructure dependencies matter: In this case, DNS resolution and internal load-balancer health (rather than an obvious external attack) caused the disruption.[7]
With a clear map of your systems and their dependencies, you can move on to evaluating how well your vendors can handle disruptions.
Evaluating Vendor Resilience and Recovery Capabilities
After identifying the key dependencies, it’s time to assess how prepared your vendors are to recover from potential disruptions. Request their disaster recovery and business continuity plans, and don’t just take their word for it - verify the details. Look into their Recovery Time Objectives (RTO) and Recovery Point Objectives (RPO). Make sure they maintain geographically distinct, immutable, and isolated backups.
Review their Service Level Agreements (SLAs) to see what uptime guarantees they offer and check if they hold certifications like ISO 27001, SOC 2, or HITRUST CSF. These certifications are critical for ensuring they meet industry security standards. Strong recovery capabilities are not just about keeping systems running - they also protect patient safety. Consider this: healthcare breaches incur an average cost of $7.42 million, the highest across all industries for 14 years straight[6]. This makes vendor security a financial necessity as much as a technical one.
Leveraging Censinet RiskOps™ and Censinet AITM for Risk Management
Censinet RiskOps™ provides a centralized platform to streamline third-party risk assessments. Healthcare organizations can use it to inventory all cloud assets - such as virtual machines, storage buckets, databases, and network configurations - and rank them by their criticality and sensitivity[8]. Systems that handle sensitive patient data are given top priority for additional security measures and constant monitoring.
Censinet AITM further simplifies the process by automating security questionnaires. It summarizes evidence, captures integration details, identifies fourth-party exposures, and produces concise risk summary reports. This blend of human oversight and automated processes reduces the time spent on assessments while maintaining accuracy.
With an intuitive dashboard that aggregates real-time data, Censinet RiskOps acts as a command center. It allows organizations to visualize dependencies, track vendor performance, and ensure critical findings are routed to the right people for prompt action. These tools help centralize and streamline risk assessments, ensuring that technical safeguards align with the overall goal of maintaining healthcare operational continuity.
Building Healthcare IT Systems That Survive Outages
Making Applications and Data More Resilient
Creating a resilient healthcare IT system means building redundancy into every layer - power, network paths, servers, and data storage. For example, Guy's and St Thomas' Hospital employs Azure Cloud's regional redundancy to ensure that backups activate immediately, keeping patient access uninterrupted[9].
Deploying systems across multiple geographic regions is crucial for mission-critical healthcare applications. This approach guards against regional disasters and localized outages by mirroring data centers in separate locations. A great example is FDB Vela's multi-region setup on Microsoft Azure, which not only improves availability but also supports advancements in ePrescribing[9].
Automatic failover mechanisms are equally important. These systems instantly switch to backup components or locations when the primary system fails. To make this work, continuous monitoring tools are essential - they track system health in real time and trigger automated responses like load balancing or failover. Considering that system downtime costs healthcare organizations an average of $7,900 per minute[10], these safeguards provide immense value by minimizing disruptions.
These strategies collectively ensure that healthcare IT systems remain operational, even during unexpected outages.
Maintaining Network and Identity Access During Failures
Network resilience requires multiple pathways and DNS redundancy. Even if applications are functioning, failures in DNS or load balancers can block access. By establishing diverse network routes and employing DNS failover strategies, organizations can maintain access to critical services.
For identity and access management, fallback authentication methods are essential. Local authentication servers, cached credentials, or alternative identity verification systems ensure that clinicians can still access patient records when external identity services are unavailable. These measures are vital for maintaining continuity in patient care.
Backup Procedures for System Failures
While automated failover is crucial, robust backup procedures play a key role during prolonged outages.
Tested downtime protocols ensure that operations can continue seamlessly. For instance, Taylor Healthcare's iMedDowntime solution resides on individual workstations, providing instant access to clinical forms and patient data even when EHR or ADT systems are offline. Additionally, downtime boxes stocked with paper charts and forms enable critical care delivery to proceed, albeit in a controlled, degraded mode[4].
Training staff on manual workflows - like using paper for documentation, medication administration, and lab result recording - is equally important. Regular practice builds confidence and ensures readiness for such scenarios[11].
Healthcare organizations are also required by the HIPAA Security Rule to have contingency plans for maintaining patient care during system downtime[10]. Beyond meeting regulatory standards, conducting regular drills and simulations helps test these plans and prepares staff to transition smoothly to backup modes. After each incident, a thorough review should be conducted to analyze what went wrong, assess the response, and implement improvements to prevent future occurrences. These steps are essential for continuous improvement and resilience in healthcare IT systems.
sbb-itb-535baee
Making Risk Management Part of Daily Operations
Managing provider failure risks isn’t a one-time task - it requires ongoing attention through a proactive Enterprise Risk Management (ERM) framework [12][13][14]. This means treating risks from cloud and third-party providers with the same level of seriousness as clinical, operational, and financial risks.
Instead of relying solely on recovery measures, organizations need to plan ahead for the inevitable - provider outages [3][15][2].
Setting Governance and Vendor Management Standards
Building resilience starts with strong contracts and clear service level agreements (SLAs). When working with cloud and third-party providers, healthcare organizations should negotiate terms that explicitly define uptime requirements, failover capabilities, and recovery time objectives (RTOs). Contracts should also detail responsibilities during outages, outline communication protocols, and include financial penalties for failing to meet SLAs.
Vendor management should prioritize resilience from the very beginning. Before onboarding a vendor, assess their disaster recovery capabilities, geographic redundancy, and historical uptime performance. Review their incident response procedures and verify that they conduct regular testing. Tools like Censinet RiskOps™ and Censinet AITM™ can help organizations integrate resilience assessments during vendor onboarding and monitor ongoing performance with ease.
A robust governance framework is essential for accountability. Assign team members to monitor vendor health metrics, review incident reports, and maintain an updated inventory of critical dependencies. This ensures that risks are closely tracked and addressed without gaps.
Testing Systems and Preparing for Incidents
Theoretical plans are only as good as their execution. Regular testing, such as full-scale simulations, tabletop exercises, and targeted drills, helps uncover weaknesses and improve response times. These tests should mimic real-world scenarios to prepare staff for actual outages - not just hypothetical situations.
Key areas to test include alternative communication methods, manual clinical documentation processes, and access to backup records and emergency protocols. For example, if your primary electronic health record (EHR) system relies on cloud authentication, ensure that clinicians can still access patient data using cached credentials or local authentication servers. Downtime procedures should be stress-tested under realistic conditions, not just reviewed on paper.
To make testing meaningful, adopt the Plan-Do-Study-Act (PDSA) cycle. This approach allows you to document successes and shortcomings after each drill, driving continuous improvement. Track metrics such as the time it takes to switch to backup systems, the frequency of access issues, and the effectiveness of communication protocols. Use these insights to refine your processes before the next test.
Real-time monitoring is another critical element. Implement tools that track the performance of both internal systems and key third-party services. Set up alerts to notify your team of any performance issues so that contingency plans can be activated immediately.
Learning from Outages to Improve Future Response
Every outage - whether it impacts your organization or happens elsewhere - offers valuable lessons. For example, the October 2025 AWS outage revealed vulnerabilities and response challenges that healthcare organizations can learn from. Conduct detailed post-mortems after such incidents to identify weaknesses in your systems and procedures.
Document the timeline of events, the impact on clinical and business operations, and how well your team responded. Pinpoint specific issues, such as unnoticed dependencies, ineffective communication channels, or difficulties executing backup procedures. These findings should directly influence updates to your risk management strategies.
Sharing these lessons across your organization and with peers can strengthen resilience on a broader scale. Joining information-sharing networks allows you to exchange insights about provider risks and effective mitigation strategies.
Finally, keep your risk assessments current. The provider landscape is always changing due to vendor mergers, infrastructure updates, and new vulnerabilities. Tools like Censinet RiskOps™ can centralize this information, providing real-time dashboards that ensure critical updates are reviewed by the right stakeholders. This dynamic approach helps healthcare organizations stay prepared for future challenges and maintain a resilient infrastructure.
Conclusion: Creating Durable Healthcare IT Infrastructure
Resilience isn't just a buzzword - it's the backbone of any effective healthcare IT strategy. As we've seen, building resilient systems requires more than just patching gaps after issues arise. It demands a shift in how we approach risk, embedding resilience into every layer of infrastructure, from system design to vendor contracts. The AWS outage in October 2025 was a wake-up call, proving that no provider is immune to disruption. Healthcare organizations must prepare for the unexpected because the stakes are simply too high.
The key lies in focusing on entire workflow resilience rather than isolated components. Protecting complete patient and clinician workflows ensures that critical processes - like emergency admissions, surgical procedures, or medication management - can continue, even during a crisis. By examining how applications, APIs, and third-party systems interact under stress, you can uncover weak points before they lead to failure.
Another cornerstone is risk-based investment prioritization. Not all systems require the same level of protection, but critical workflows absolutely do. Categorize these workflows - mission critical, business critical, operational, or administrative - and allocate resources to safeguard the most vital ones. Robust backup plans for mission-critical pathways ensure that patient care remains uninterrupted, no matter the circumstances.
Proactive strategies replace reactive chaos. This includes strong vendor oversight, rigorous testing, and ongoing improvements based on lessons learned. Tools like Censinet RiskOps™ and Censinet AITM™ can help streamline this process, offering real-time insights into vendor performance, system dependencies, and risk management workflows. These tools provide the visibility needed to adapt to an ever-changing IT landscape.
In healthcare, downtime isn't an option. By anticipating disruptions, fostering collaboration, and strengthening every layer of your infrastructure, you can ensure continuous, safe patient care. Durable healthcare IT is built one step at a time, with each improvement laying the foundation for greater resilience in the face of future challenges.
FAQs
What steps can healthcare organizations take to maintain operations during a cloud provider outage?
Healthcare organizations can keep their systems running even during a cloud provider outage by adopting multi-cloud and multi-region strategies. These methods spread resources across multiple providers or locations, making sure essential tools like EHRs, telemedicine platforms, and patient monitoring systems stay up and running.
Another key step is building redundant architectures and setting up strong disaster recovery plans. Regularly testing these plans through drills ensures teams are ready to handle disruptions quickly, reducing downtime. These efforts help maintain uninterrupted care, even when the unexpected happens.
How can healthcare organizations build IT systems that stay reliable during outages?
Building a strong and reliable healthcare IT system means preparing for disruptions before they happen. Here's how organizations can stay ahead:
- Assess risks: Pinpoint critical systems and identify weak spots to focus on reducing potential risks effectively.
- Build redundancy: Set up backup systems and failover processes to keep things running smoothly, even during outages.
- Work with multiple vendors: Spread out your reliance by partnering with several providers to lower the risk of service interruptions.
- Plan for quick recovery: Put systems in place to restore endpoints and critical operations quickly, cutting down on downtime.
- Test contingency plans: Create detailed disaster recovery and continuity plans specifically for healthcare, and make sure to test them regularly.
By sticking to these steps, healthcare organizations can protect both patient care and operational flow, even when unexpected challenges arise.
How does Censinet RiskOps™ help healthcare providers manage risks effectively?
Censinet RiskOps™ simplifies the complex world of risk management for healthcare providers by delivering full transparency into third-party and vendor risks. By automating risk assessments, it allows organizations to pinpoint vulnerabilities swiftly and take action before they escalate into major problems.
The platform also offers continuous monitoring and supports compliance with regulations like HIPAA. This ensures healthcare systems stay prepared for challenges such as cloud outages or vendor disruptions, helping to protect essential operations and maintain uninterrupted patient care.
Related Blog Posts
- When Multi-AZ Isn't Enough: What the AWS US-EAST-1 Failure Taught Us About True Resilience
- 7 Hours Down, Millions Affected: Inside the AWS Outage That Broke Healthcare's Digital Backbone
- The AWS Outage Exposed Cloud Vulnerabilities - What It Means for Healthcare Business Continuity
- The AWS Outage and Joint Commission: How Business Continuity Standards Just Got Harder
