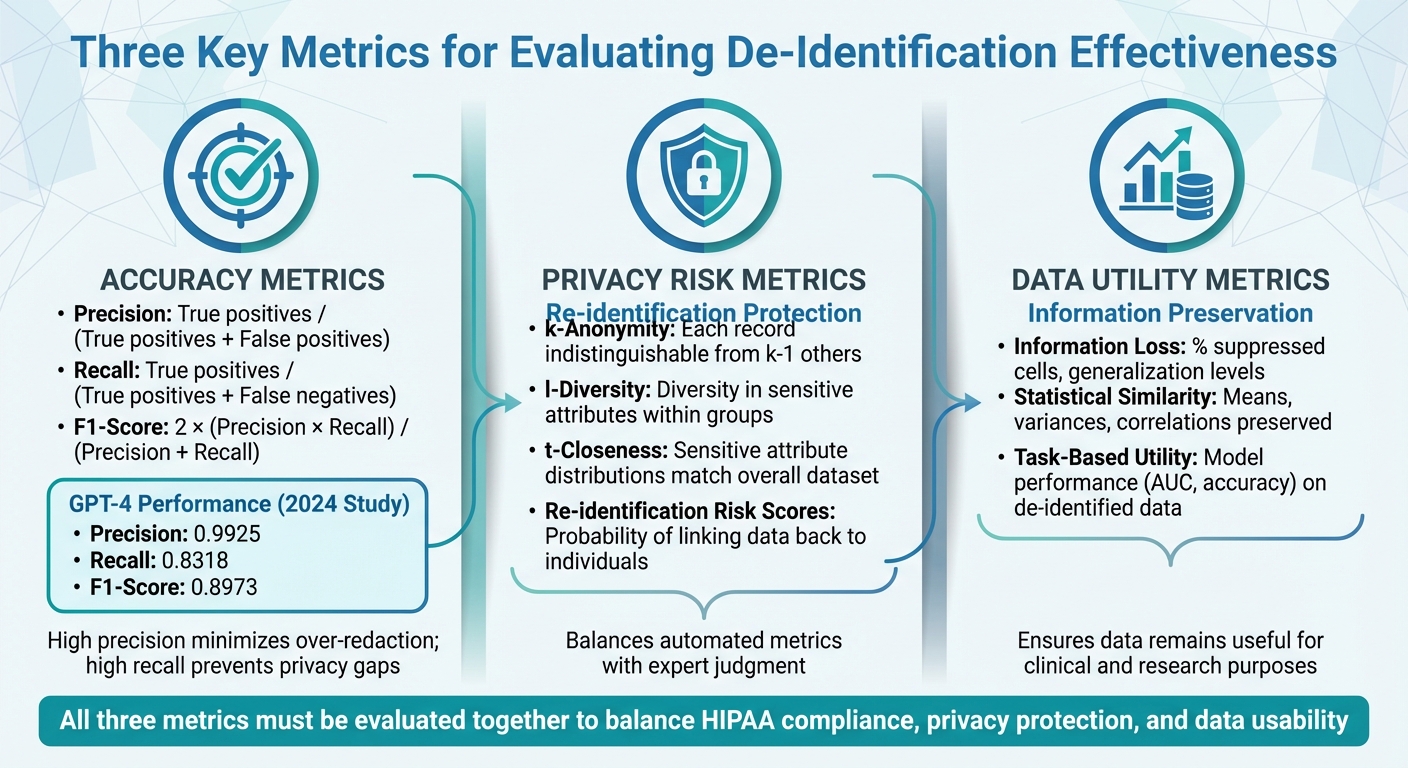
De-identification in healthcare is the process of removing identifiable information from datasets to protect patient privacy while maintaining data usability. This practice is critical for HIPAA compliance and safe data sharing. However, achieving the right balance between privacy and utility requires careful evaluation using three key metrics:
- Accuracy: Precision, recall, and F1-score measure how effectively PHI (Protected Health Information) is detected and removed.
- Privacy Risk: Metrics like k-anonymity and re-identification risk estimate the potential for linking de-identified data back to individuals.
- Data Utility: Evaluates how much information is preserved and whether the data remains useful for clinical or research purposes.
Standardized datasets, such as i2b2 for clinical text or MIDI-B for medical imaging, help healthcare organizations test tools and set performance benchmarks. For example, a 2024 study showed GPT-4 achieving high precision (0.9925) but lower recall (0.8318), highlighting trade-offs between over-redaction and missed PHI. Tools like Censinet RiskOps™ integrate these evaluations into broader risk management workflows, enabling organizations to align de-identification practices with privacy laws while retaining data value.
To ensure effective de-identification:
- Set clear performance thresholds for accuracy, privacy, and utility.
- Use benchmark datasets to test tools and compare results.
- Regularly revalidate systems to adapt to evolving risks and data needs.
Balancing privacy and utility is essential for compliance, research, and patient trust.
Three Key Metrics for Evaluating Healthcare De-Identification Effectiveness
Key Metrics for Measuring De-Identification Effectiveness
Measuring the effectiveness of de-identification involves evaluating three key areas at the same time. Performance accuracy determines how well your system identifies and removes PHI (Protected Health Information) from clinical notes, structured EHR fields, or medical images. Privacy risk assesses the likelihood that de-identified data could be linked back to an individual. Data utility gauges whether the altered dataset still serves its intended clinical or research purpose. U.S. healthcare organizations have to navigate these trade-offs carefully - focusing too much on privacy can reduce data usefulness, and vice versa.
These metrics align with HIPAA's Expert Determination requirements. Let’s break down each one for better understanding.
Accuracy Metrics: Precision, Recall, and F1-Score
When it comes to accuracy, three metrics stand out: precision, recall, and F1-score.
- Precision measures how many of the flagged PHI elements are actually PHI. It’s calculated by dividing true positives by the sum of true positives and false positives. High precision minimizes the risk of over-redacting clinical terms, lab values, or non-identifying dates, ensuring records remain useful.
- Recall reflects how much PHI your system successfully identifies, calculated as true positives divided by the sum of true positives and false negatives. High recall is critical because missing PHI (false negatives) increases privacy risks and could lead to HIPAA violations.
- F1-score balances precision and recall into a single metric: F1 = 2 × (precision × recall) / (precision + recall). For example, a 2025 Nature study on GPT-4’s de-identification of clinical notes reported a precision of 0.9925, recall of 0.8318, and an F1-score of 0.8973. This highlights the trade-off: even with high precision, low recall can leave gaps in privacy protection.
Different types of data require tailored approaches. Free-text records are assessed for entity-level precision, recall, and F1. Structured EHR fields are evaluated at the field level, ensuring PHI is masked without affecting non-identifying data. For medical images, accuracy involves checking both pixel-level PHI (like burned-in names) and metadata in DICOM headers. The 2024–2025 Medical Image De-Identification Benchmark (MIDI-B) Challenge tested compliance with HIPAA’s 18 Safe Harbor identifiers and DICOM confidentiality standards, using 400 imaging studies across CT, MR, PET, and other modalities.
Privacy Risk Metrics: k-Anonymity and Re-Identification Risk
Once accuracy is measured, assessing privacy risks is the next step.
- k-Anonymity ensures that each record in your dataset is indistinguishable from at least k-1 others based on quasi-identifiers like age, gender, and ZIP code. For example, a dataset with k=5 means each record blends into a group of at least five.
- l-Diversity goes further by requiring diversity in sensitive attributes (like diagnoses) within each k-anonymous group, ensuring that everyone in a group doesn’t share the same condition.
- t-Closeness takes it up a notch by ensuring that sensitive attribute distributions within groups closely match the overall dataset, reducing the risk of unintended disclosure.
Re-identification risk scores estimate the probability of linking de-identified records back to individuals using external data or unique identifiers. These scores depend on factors like the uniqueness of quasi-identifiers and the sophistication of potential adversaries.
The MIDI-B Challenge acknowledged that actual re-identification risk is "indeterminable" and must be approximated through surrogate metrics. These include compliance checks (removal of Safe Harbor elements) and evaluations of preserved metadata that could enable re-linking. For U.S. healthcare organizations, this means balancing automated metrics with expert judgment to account for specific use cases, data recipients, and potential threats.
Data Utility Metrics: Information Loss and Clinical Value
Finally, ensuring the de-identified data retains its usefulness is critical.
- Information-loss metrics measure how much detail is lost during de-identification processes like generalization, suppression, or date shifting. Examples include the percentage of suppressed cells, average generalization levels (e.g., reducing ZIP codes from five digits to three), or distortion indices for continuous variables like lab values. The acceptable level of information loss depends on the intended use of the data.
- Statistical similarity metrics compare the distributions and relationships in the original and de-identified datasets. Metrics like means, variances, correlation coefficients, and chi-square statistics help ensure that key patterns, trends, and clinical relationships remain intact.
- Task-based utility metrics evaluate how de-identification impacts downstream applications. For instance, if a predictive model is trained on both original and de-identified data, comparing metrics like AUC, calibration, or error rates can reveal whether performance remains within acceptable limits.
Modern benchmarks for de-identification, particularly for clinical text and medical imaging, combine PHI detection accuracy with assessments of metadata and usability. This joint evaluation ensures that healthcare organizations can confidently use de-identified data for quality improvement projects, clinical trials, and analytics while maintaining privacy compliance. Platforms like Censinet RiskOps™ integrate these utility checks into broader risk management workflows, helping organizations align de-identification practices with both regulatory and operational needs.
Benchmark Datasets and Standards for De-Identification
When it comes to evaluating de-identification tools, having standardized datasets and clear benchmarks is essential. U.S. healthcare organizations need reliable ways to compare vendors, validate their systems, and ensure compliance. Benchmark datasets provide annotated examples of real clinical data, and regulatory standards define what qualifies as acceptable performance. Together, these elements create a solid foundation for objective evaluation. Below, we’ll dive into benchmarks for text-based and imaging datasets, as well as regulatory standards.
Text-Based Datasets and PHI Annotation Standards
The 2006 i2b2/PhysioNet de-identification challenge introduced a widely used benchmark: discharge summaries annotated for detailed PHI categories. These include patient names, relative names, clinician names, dates, locations, contact information, IDs, and other identifiers [4]. This dataset followed a clear method: annotate clinical text according to HIPAA's 18 Safe Harbor identifiers, then evaluate how well tools identify and remove each category.
In 2014, the i2b2/UTHealth "de-identification of longitudinal medical records" challenge expanded on this by using a larger and more complex dataset of longitudinal clinical narratives [4]. This benchmark became the go-to for evaluating modern approaches, especially as neural networks and large language models entered the scene. Evaluations typically rely on entity-level metrics like precision, recall, and F1-score, measured under strict (exact match) or relaxed (partial match) criteria [4][3].
Standardized benchmarks highlight significant differences in how vendors perform. Testing multiple de-identification systems on the same dataset can expose gaps, such as whether tools detect PHI partially or fully - insights that marketing claims often fail to reveal [3].
Medical Imaging and DICOM De-Identification Standards
While text datasets shape PHI annotation standards, imaging data comes with its own challenges. Medical images contain PHI within both DICOM header metadata and pixel data. The DICOM Attribute Confidentiality Profiles (outlined in DICOM PS3.15/PS3.16) specify which header attributes include PHI and how to handle them - whether by removing, replacing, or generalizing [1]. These profiles act as both technical specifications and benchmarks.
In 2024, the Medical Image De-Identification Benchmark (MIDI-B) Challenge, organized by the National Cancer Institute, MICCAI, and Sage Bionetworks, provided the first comprehensive benchmark for DICOM de-identification [1]. This challenge tested tools using data from 352 patients and 400 studies across modalities like CR, MR, CT, PET, DX, SR, MG, and US. The tools were evaluated against HIPAA Safe Harbor, DICOM confidentiality profiles, and TCIA best practices [1]. The challenge treated these standards as proxies for assessing re-identification risk [1].
The Cancer Imaging Archive (TCIA) serves as both a benchmark and a practical reference. TCIA distributes research imaging collections that comply with strict de-identification rules, such as removing PHI-bearing DICOM tags and obscuring burned-in annotations. Organizations can use TCIA’s protocols as a checklist to determine what should be removed or retained in DICOM headers and pixel data, particularly when preparing datasets for research [1].
Regulatory Standards as Performance Benchmarks
Regulatory benchmarks like HIPAA Safe Harbor and DICOM confidentiality profiles set the baseline for de-identification accuracy and privacy. HIPAA’s Safe Harbor method outlines 18 identifiers that must be removed to meet compliance. If a tool misses any of these identifiers, it fails the compliance test. The Expert Determination method, on the other hand, requires statistical and scientific analysis to ensure re-identification risk is "very small." This often translates into measurable thresholds for k-anonymity, re-identification scores, and data utility.
DICOM standards provide detailed guidelines for imaging data. For example, MIDI-B assessed tools against the DICOM PS3.16 Basic Confidentiality Profile and NEMA-specified options, along with TCIA best-practice rules that balance PHI removal with preserving metadata critical for research [1]. This dual focus ensures that data remains both secure and useful.
Some institutions go beyond federal standards, imposing stricter requirements. These might include removing quasi-identifiers like rare occupations, small facilities, or uncommon procedure combinations. They may also require more aggressive date shifting or tighter controls on free-text comments and burned-in annotations [1][5]. Organizations can encode these stricter policies into rule sets or annotation schemas, then measure compliance, residual PHI, and data utility under their own standards, rather than relying solely on federal guidelines [1][5]. Platforms like Censinet RiskOps™ help integrate these benchmarks into broader risk management workflows, ensuring that de-identification practices align with both regulatory and operational goals.
Balancing Privacy Protection and Data Utility
De-identification in healthcare requires a careful balance between protecting privacy and maintaining the usefulness of data. Stricter masking can safeguard sensitive information but often diminishes the value of datasets for research, clinical analysis, or projects like AI model development. U.S. healthcare organizations must navigate this challenge thoughtfully, tailoring their approach to the specific needs of each dataset and its intended application [5]. The choice of de-identification method plays a central role, as the effectiveness of these techniques varies widely.
Comparing De-Identification Models: Recent Research Findings
Rule-based systems operate using predefined patterns to identify and remove Protected Health Information (PHI). For example, they can detect Social Security numbers or standard date formats with high precision. These systems are straightforward, aligning well with HIPAA Safe Harbor requirements. However, they often over-mask, removing entire sections of text when only a portion might be sensitive. This can disrupt the narrative flow and erase clinically important details [4].
Machine learning–based named entity recognition (NER) models take a more dynamic approach by learning from annotated examples. These models adapt better to new formats and typically achieve higher recall when identifying unstructured PHI. A 2021 study on deep learning techniques for de-identification reported impressive F1-scores of around 0.95 for PHI recognition in i2b2 clinical text [4]. Despite this, they rely heavily on high-quality training data and may struggle when applied to unfamiliar institutions or documentation styles.
Large language models (LLMs) like GPT-4 represent a newer frontier. A 2024 study in Nature highlighted GPT-4's strong performance in de-identifying clinical notes, with precision at 0.9925, recall at 0.8318, an F1-score of 0.8973, and accuracy of 0.9911 - all in a zero-shot setting [2]. High precision is particularly valuable as it reduces false positives and retains more non-PHI clinical content. GPT-4 also outperformed GPT-3.5 across all key metrics [2], showcasing its ability to follow detailed instructions, such as "mask day and month but keep the year" or "redact ages 90 and above only" [2][5]. However, concerns about cost, processing time, and PHI governance in API workflows remain.
Many organizations now implement hybrid systems that combine rules, ML models, and LLMs. For instance, a hybrid system applied to psychiatric notes achieved a de-identification accuracy of 90.74% [2]. These workflows often use deterministic rules for high-risk identifiers like Social Security numbers while relying on data-driven models for more context-sensitive entities, such as geographic locations or clinician names [4][2].
How Over-Redaction Affects Data Utility
Overly aggressive de-identification can strip away information vital for analysis, even when HIPAA guidelines don’t require full suppression [5]. One clear example is dates: replacing all dates with generic placeholders like "[DATE]" can erase critical temporal patterns needed for studies on hospital stays, medication adherence, or time-to-event outcomes. HIPAA, however, allows organizations to retain the year while masking the day and month, preserving some of this context [2][5].
Geographic details face similar challenges. Removing all geographic markers can hinder analyses of regional health disparities or environmental risks. HIPAA permits the use of three-digit ZIP codes under certain conditions, offering a compromise that retains some spatial data while managing re-identification risks [5]. Blanket removal forfeits this middle ground.
Over-redaction can also affect rare conditions or detailed procedure descriptions, making it difficult to define patient cohorts for specialty registries or device monitoring. Similarly, removing all clinician and facility identifiers can obstruct quality improvement efforts that rely on comparing care pathways or spotting variations in practice. The 2024 Medical Image De-Identification Benchmark (MIDI-B) revealed that some DICOM de-identification tools excessively strip metadata, not just PHI, reducing their utility for multi-center studies and AI benchmarking [1]. These examples highlight how excessive redaction can undermine critical clinical insights, emphasizing the need for balanced strategies.
Risk Management Implications of Privacy-Utility Tradeoffs
To manage these tradeoffs effectively, organizations must establish clear performance thresholds tailored to each use case. For external data sharing, where privacy risks are higher, stricter measures like Safe Harbor plus additional suppression may be necessary, even if it limits analytic power [5]. For internal research in controlled environments, an Expert Determination approach may be more appropriate, allowing retention of certain details like years, coarse geographic data, and essential codes under strict access controls [5][6].
Metrics like k-anonymity help quantify privacy risks by measuring how distinguishable a patient is within a dataset. Achieving higher k-values often requires generalizing or suppressing data, such as grouping ages into bands or using broader geographic categories. While this reduces the risk of re-identification, it can also limit the granularity needed for analyzing rare conditions or small populations. Organizations often refine their approach iteratively: they set a risk threshold, apply transformations, assess the impact on key analyses (e.g., changes in predictive model performance), and adjust until they strike a balance between privacy and utility [4][5].
Platforms like Censinet RiskOps™ support healthcare organizations in aligning de-identification practices with both regulatory requirements and operational goals. By taking a structured, case-specific approach, organizations can address privacy concerns while preserving the data’s value for meaningful clinical and research applications. This ensures compliance without resorting to overly simplistic, one-size-fits-all solutions.
sbb-itb-535baee
Applying Benchmarks in U.S. Healthcare Organizations
This section delves into how U.S. healthcare organizations put metrics and benchmarks into practice, focusing on de-identification standards and risk management processes.
Setting Performance Thresholds for De-Identification
Healthcare organizations must establish clear performance goals that align with HIPAA requirements and operational priorities. For clinical text, this often means achieving F1-scores of at least 0.90 and precision above 0.99 for high-risk identifiers like Social Security numbers, medical record numbers, and patient names [2][3]. High precision reduces false positives, ensuring accurate identification of Protected Health Information (PHI). At the same time, recall is critical to avoid missing identifiers, even if it occasionally results in over-redaction for lower-risk fields.
In the case of DICOM imaging, thresholds should adhere to HIPAA Safe Harbor guidelines, DICOM profiles, and best practices from organizations like TCIA [1]. These standards help hospitals evaluate how effectively de-identification tools remove PHI from DICOM headers and burned-in annotations while keeping essential metadata intact, such as acquisition parameters and study dates.
Organizations should also define data utility thresholds based on the intended use of the data. For example, acceptable limits might include "no more than a 2–3% relative decrease in AUC for priority predictive models" or specific thresholds for patient inclusion rates. For clinical text, this involves maintaining consistent distributions of critical variables - diagnoses, procedures, medications, lab values, and outcomes - after de-identification [7][2]. For imaging, utility metrics might focus on preserving acquisition parameters, lesion visibility, and diagnostic accuracy in AI models or radiologist evaluations [1].
3-Axis Evaluation Framework for De-Identification
To operationalize these performance targets, organizations can use a three-axis evaluation framework that focuses on privacy, utility, and operational performance.
- Privacy risk: This measures residual identifiers, k-anonymity levels, and re-identification risks, as outlined in HIPAA's Expert Determination. It includes tracking missed-PHI rates and simulating re-identification using public data.
- Data utility: This examines how de-identification impacts downstream tasks, such as model performance (AUC, accuracy), cohort selection, and the completeness of clinical documentation. The goal is to ensure de-identified data supports comparable analytical outcomes and remains interpretable for clinicians.
- Operational performance: This evaluates throughput (records processed per hour), latency per note or study, error rates, and how well de-identification tools integrate with systems like EHRs, PACS, and data warehouses.
This framework allows organizations to tailor thresholds to specific use cases. For example, external data sharing for commercial partnerships might require stricter privacy measures and higher k-anonymity values, even if it reduces data granularity. Conversely, internal quality improvement projects in controlled environments might accept lower k-values to retain more detail, provided access controls are robust. Balancing all three axes ensures data remains both secure and usable.
Using Benchmarks in Risk Management Workflows
Incorporating benchmarks into risk management processes strengthens data protection and compliance efforts. Healthcare organizations should form a multidisciplinary team that includes privacy, security, clinical, data science, and legal experts. This team is responsible for setting de-identification benchmarks, selecting tools, and reviewing performance reports to ensure alignment with HIPAA and internal policies [5][6]. Documentation should detail expert determinations, k-anonymity methodologies, benchmark dataset composition, chosen thresholds, and the rationale behind these decisions [5].
Platforms like Censinet RiskOps™ help streamline this process by enabling organizations to manage risks related to patient data, PHI, clinical systems, and third-party vendors within a unified framework. For instance, de-identification benchmarks can be integrated into vendor risk assessments, ensuring that third-party tools meet data protection and compliance standards.
Routine monitoring is also essential. Organizations should periodically re-test de-identification systems using internal benchmark datasets that reflect their specific clinical environments, such as inpatient, outpatient, emergency, and specialty care domains [7][4][3]. For text, this might involve creating a dataset tailored to local templates, abbreviations, and macros. For imaging, a representative set of DICOM studies should include various modalities and vendors, focusing on header fields and burned-in annotations that pose HIPAA risks [1][5]. Automated testing tools can measure precision, recall, F1 scores, metadata compliance, and execution time, ensuring consistent evaluation and adaptation to system changes or upgrades.
Conclusion
Assessing the effectiveness of de-identification calls for more than just ticking boxes on a checklist. U.S. healthcare organizations need well-defined, objective metrics for protected health information (PHI) to ensure their methods meet regulatory standards while maintaining the data’s clinical and research integrity. Without these benchmarks, organizations risk falling short in demonstrating to regulators, boards, or patients that PHI is adequately safeguarded. They also face challenges in confidently using de-identified data for purposes like AI development, quality improvement, or population health analytics. These metrics form the backbone of risk management and evaluation processes.
Striking the right balance between privacy and usability is crucial, as it directly affects patient care, research quality, and risk management outcomes. Overzealous redaction can weaken longitudinal studies and impair model training, while insufficient redaction increases the risk of re-identification and regulatory penalties. For instance, recent findings revealed that GPT-4 achieved a precision of 0.9925 in clinical note de-identification but only managed a recall of 0.8318, highlighting that even advanced tools can miss PHI [2]. To address this, organizations need to establish clear target ranges for privacy protection and acceptable information loss, tailored to specific scenarios like external data sharing versus internal quality initiatives.
Benchmarks play a critical role in tool selection by allowing healthcare organizations to evaluate potential tools against standardized performance metrics before implementation. For example, MIDI-B validated tools across both privacy and utility dimensions, demonstrating the value of benchmarks that combine these criteria [1]. Similarly, text de-identification benchmarks enable organizations to assess entity-level performance across various PHI categories, ensuring that chosen tools align with their risk tolerance and operational goals.
Platforms like Censinet RiskOps™ build on these benchmarks by embedding them into broader risk management workflows. By integrating PHI metrics into third-party risk assessments, organizations can verify that vendor tools meet stringent data protection and compliance requirements. Benchmarking against industry standards equips healthcare organizations to advocate for necessary resources and lead in critical areas. Establishing clear performance thresholds and conducting regular revalidation ensures that de-identification benchmarks are seamlessly incorporated into risk management strategies. This unified approach allows organizations to manage risks tied to patient data, clinical systems, and vendor relationships within a single framework.
Federal guidance from the Department of Health and Human Services (HHS) emphasizes that de-identification under the Expert Determination method must be well-documented and periodically reviewed as data environments and re-identification risks evolve. Healthcare organizations should set multi-metric performance goals, routinely revalidate de-identification systems using internal benchmark datasets, and maintain thorough records for regulators and boards. These records should detail the methods used, benchmarks applied, and the tradeoffs accepted between privacy and utility. This metrics-driven approach has become a cornerstone of responsible data management in U.S. healthcare, enabling safer data sharing, upholding public trust, and reducing legal risks.
FAQs
What is the relationship between accuracy, privacy risk, and data utility in de-identification?
In de-identification, three crucial elements come into play: accuracy, privacy risk, and data utility. Accuracy ensures that the de-identified data remains faithful to the original information. Privacy risk gauges the chances of someone being able to re-identify individuals from the data. Meanwhile, data utility measures how well the de-identified data serves its intended purpose.
These factors are tightly interwoven. For instance, enhancing accuracy might inadvertently raise privacy risks, while lowering privacy risks could reduce how useful the data is. The challenge lies in striking the right balance. Effective de-identification techniques aim to keep the data practical for its intended use while minimizing the chances of re-identification - achieving a harmony between privacy and functionality.
What makes it difficult to balance privacy and data usability in healthcare de-identification?
Balancing patient privacy with the practical use of healthcare data is no easy task. If too much information is removed to protect privacy, the data can lose its value for research and analysis. On the flip side, leaving in too much detail can heighten the risk of re-identification, potentially exposing sensitive patient information.
To navigate this challenge, healthcare organizations turn to proven metrics and benchmarks to assess de-identification techniques. These tools play a key role in ensuring that data stays secure while still being useful, enabling important progress in patient care and medical research.
Why is it essential to regularly review and update de-identification systems in healthcare?
Keeping de-identification systems up-to-date is crucial for protecting patient privacy and addressing new challenges. As healthcare data continues to grow in complexity - with new formats and types emerging - regular updates ensure these systems remain reliable and secure against increasingly sophisticated threats.
Routine revalidation also plays a key role in meeting privacy standards, minimizing the likelihood of re-identification, and reducing the chance of data breaches. By actively identifying and fixing vulnerabilities, healthcare organizations can safeguard sensitive patient information and uphold the trust of those they serve.
