In healthcare, even a few minutes of system downtime can put lives at risk. Automated failover systems are transforming how hospitals manage IT failures by detecting issues and switching to backup systems in seconds. This ensures uninterrupted access to patient records, emergency services, and critical applications. Traditional manual failover methods take hours, increasing risks to patient safety, compliance, and financial stability.
Key Takeaways:
- Why downtime matters: IT failures disrupt patient care, delay treatments, and risk non-compliance with regulations like HIPAA.
- Automated failover benefits: Reduces recovery times (RTO) to minutes and minimizes data loss (RPO) with continuous synchronization.
- Risks of legacy systems: Manual processes lead to delays, errors, and increased costs during outages.
- Implementation essentials: High-availability power, SD-WAN, database failover, and regular testing ensure readiness.
Automated failover is critical for maintaining uninterrupted healthcare operations, improving patient outcomes, and meeting compliance standards.
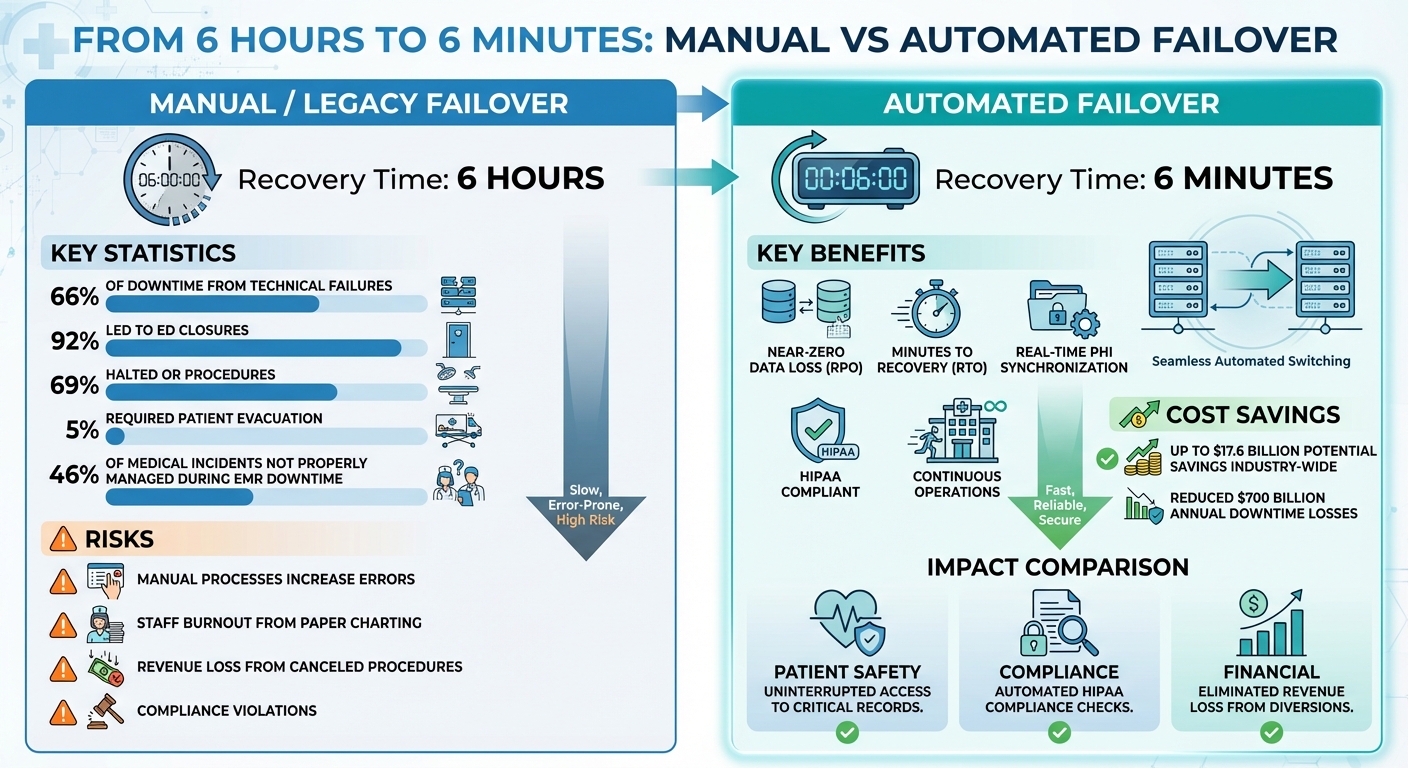
Manual vs Automated Failover Systems in Healthcare: Recovery Time and Impact Comparison
Risks of Legacy Failover Systems
Unlike automated failover systems, legacy approaches come with serious risks that can disrupt operations and jeopardize patient safety. These older systems often rely on manual processes, which increase the chance of delays and errors - issues that can ripple through patient care and even affect a healthcare facility's financial health.
Common IT Failures in Healthcare
Technical failures are a major source of downtime in healthcare, accounting for 66% of such events [7]. Between 2000 and 2020 in the Netherlands, 85% of IT failures were categorized as primary IT failures, often tied to issues with hospital software or computer networks [9]. The consequences of these failures are severe: 92% led to emergency department closures, 69% halted operating room procedures, and 5% required evacuating patients to other facilities [9].
Real-world examples highlight the gravity of these risks. In December 2022, a water leak above an electric breaker room caused an electrical fire at a multispecialty group practice. This led to a complete power loss and drained the backup server batteries before the IT team could act. The result? An uncontrolled shutdown that corrupted the EHR formulary database and administrative file server. While the EHR was restored after 48 hours, administrative functions were disrupted for over a week due to data loss and difficulties with restoring backups [8]. Similarly, a 2018 hardware failure in a Dutch academic hospital caused a five-hour emergency department diversion, further illustrating the operational and financial strain caused by IT failures [9].
Financial and Operational Costs of Downtime
The financial toll of downtime is far-reaching. Beyond the immediate costs of IT repairs, manual processes during outages are significantly more expensive than digital ones. For instance, healthcare facilities could save up to $17.6 billion by adopting more efficient technologies [10]. During system failures, hospitals lose revenue from canceled procedures, patient diversions, and extended disruptions.
Operationally, the burden falls heavily on staff, who must revert to manual tasks like paper charting, handling prescription refills via phone, and physically scanning insurance cards. These manual processes increase workloads, contribute to staff burnout, and amplify inefficiencies. Revenue losses from missed appointments and canceled procedures further underscore how outdated systems create unnecessary financial strain - problems that modern technology can help resolve [10].
Patient Safety and Compliance Risks During Downtime
The risks tied to legacy systems go beyond money - they directly impact patient safety and compliance. Even short outages can disrupt critical care. For example, a CPOE interface that failed to display medication doses in milligrams led to a patient receiving three times the maximum dose of an analgesic, causing acute renal failure and death [9]. Such incidents underscore how system failures can have life-threatening consequences.
Compliance is another area of concern. Regulations like HIPAA demand strong encryption, access controls, and cybersecurity measures to protect sensitive patient data [11]. Failures in legacy systems can expose organizations to data breaches and privacy violations. As Margaret Chustecki from Yale School of Medicine warns, “AI systems should be protected from privacy breaches to prevent psychological and reputational harm to patients” [12]. When patient data isn’t secure during outages, healthcare providers face penalties, regulatory scrutiny, and additional operational challenges - all while trying to maintain patient trust.
Core Components of Automated Failover Systems
Automated failover systems are designed to maintain continuous operations and minimize downtime by seamlessly switching to backup resources during failures. They rely on solid backup protocols, advanced hardware, and features like automatic switching, diverse connectivity options, and load balancing to ensure reliability [3].
Technical Architecture for Automated Failover
Building a failover system that can handle disruptions starts with a few key components. High-availability power sources are critical, including uninterruptible power supplies (UPS), emergency generators, and connections to multiple utility providers [13]. To further reduce risks, network redundancy is essential. This includes multiple links, diverse connection types, carrier diversity, and redundant devices to eliminate single points of failure [13].
Software-Defined Wide Area Networking (SD-WAN) is another vital piece of the puzzle. It utilizes various network connections - such as wired, 5G, and satellite - to dynamically route traffic based on live conditions [13][15]. For example, a retail chain using SD-WAN can maintain uninterrupted connectivity by automatically shifting traffic to alternate links when one fails. This ensures critical business applications always take the best available path, even in the face of disruptions [15].
Database failover takes over seamlessly when the primary database encounters an issue [15]. A practical example of this is InterSystems IRIS mirroring, which replicates data between two independent failover members. An arbiter system and ISCAgents monitor the setup constantly, enabling automatic failover decisions without relying on shared storage, which can be a single point of failure [5]. Virtualization platforms add another safeguard by monitoring hardware and operating systems, restarting failed virtual machines on backup hardware as needed [5].
These strategies significantly improve both Recovery Time Objective (RTO) and Recovery Point Objective (RPO), which are explored further below.
How Automation Reduces RTO and RPO
Automated failover systems are game-changers when it comes to reducing RTO and RPO. Recovery Time Objective (RTO) refers to the maximum acceptable downtime for critical systems following a disaster [19][21][22]. In industries like healthcare, where downtime can directly impact patient care, automated systems can slash RTO from hours to just minutes by instantly switching to backups [19][20].
On the other hand, Recovery Point Objective (RPO) defines the maximum acceptable data loss during an incident [19][21][22]. Continuous data synchronization ensures that critical information, such as patient records, remains intact, achieving near-zero data loss while meeting HIPAA compliance standards [19][20][21].
Advancements in failover technology continue to push these limits. For instance, SQL Server 2025 introduced a feature allowing administrators to set the RestartThreshold for Always On Availability Groups to 0 using PowerShell (Get-ClusterResource -Name "ag1").RestartThreshold = 0. This enables immediate failover when persistent health issues are detected, minimizing downtime for non-transient failures [14]. With North American enterprises losing an estimated $700 billion annually due to network and communication downtime, these improvements are more important than ever [13].
Security and Privacy in Failover Systems
Security and compliance are integral to automated failover systems, especially when sensitive data like Protected Health Information (PHI) is involved. Kirsten Peremore from Paubox highlights how these systems ensure both continuous service and secure PHI sharing [1]. To meet HIPAA requirements, backup providers must sign a Business Associate Agreement (BAA) [1].
Real-time synchronization between primary and failover systems prevents gaps in PHI storage during failover events [1]. Encryption keys must be centrally managed in a HIPAA-compliant way to ensure PHI remains encrypted at all times [1]. Automated checks verify data integrity, ensuring that PHI remains accurate and unaltered during transitions [1]. However, as Fortinet warns:
"The communication that happens during failover is inherently insecure, however. This could present an opportunity for a hacker to create a condition necessitating failover, with the intention of stealing or accessing information during failover. To ensure security, use a firewall" [17].
Firewalls should be strategically integrated into the network to block unauthorized access to failover ports [17].
InterSystems IRIS provides additional safeguards with features like write image journal (WIJ) technology, journaling, and transaction processing to maintain data integrity during failovers [5][18]. Regular testing of failover and failback processes is essential to ensure smooth transitions and prevent synchronization issues or missing PHI records [1].
How to Implement Automated Failover
Transitioning from manual to automated failover is all about careful planning and execution across three key phases. The aim? Minimize downtime, avoid service interruptions, reduce losses, maintain resilience, and enable seamless maintenance [6]. However, many hospitals face challenges with commercial failover solutions due to limited training, integration hurdles, and high costs, making a structured approach essential [23].
Assessment and Design Phase
Start with a Business Impact Analysis (BIA), an Infrastructure Audit, and a Compliance Gap Analysis to define your recovery time objectives (RTO) and recovery point objectives (RPO). These steps help identify dependencies and ensure compliance with regulations like HIPAA [20][4].
Bring together key stakeholders from IT, compliance, operations, and clinical teams to align the failover system with organizational goals and clinical workflows [20][24]. Develop detailed designs that include redundancy across networks, power, cooling, and servers [6][4]. Create a thorough implementation plan with realistic timelines, resource allocation, training schedules, and strategies to mitigate risks [24].
Phased Implementation and Testing
Once your design is ready, the next step is deployment and rigorous testing. Use hybrid disaster recovery solutions like AWS CloudEndure or Azure Site Recovery for smooth data replication [20]. Configure development or test environments with the required failover services, leveraging Infrastructure as Code (IaC) for consistency [4]. Set up a recovery site, such as a secondary AWS Region, to implement and test failover systems [4].
Automate failover mechanisms for critical infrastructure and configure orchestration scripts for quick recovery [16][20]. Define how often data synchronizes between primary and secondary systems [6]. Check quotas, autoscaling, and active resources to ensure failover readiness [4].
Testing is crucial. Simulate real-world failures using tools like AWS Fault Injection Simulator, Azure Chaos Studio, or Gremlin to test scenarios such as instance terminations, network throttling, or availability zone outages [25][26]. Gradually increase the complexity of failure scenarios and incorporate load testing to mimic actual usage during outages [26]. Monitor the behavior of load balancers and health checks, capturing metrics and recovery events [26]. Compare recovery times to your RTO and validate data integrity against your RPO [26].
In one hospital case study, during a planned 90-minute HIS downtime, 260 individuals accessed an emergency query program, and 282 users relied on an emergency prescription system. On average, it took 18 minutes and 40 seconds from prescription to execution, with 22 prescriptions issued [23]. Post-downtime surveys revealed that 86% found the query program useful, 89% found the prescription system helpful, but only 11% felt paper-based processes were always viable [23]. This highlights the importance of automation: 46% of medical incidents during EMR downtime were not properly managed [23].
Change Management and Training
After testing, focus on change management and training to ensure long-term reliability. Develop detailed failover and failback playbooks outlining every step for transitioning each resource, application, and service [4]. These playbooks should also include the steps and timing for restoring operations to the primary system [4]. Regularly rehearse these processes through simulations and chaos testing to validate both manual and automated workflows [4].
Document which failover tasks are automated and which require manual input, while measuring the RTO and RPO for each service [4]. Ensure IT teams are clear on their roles during failover events, and train clinicians on temporary workflows or emergency systems. Establish clear communication plans so staff know what to expect during tests or outages. Plan periodic testing - quarterly is a good benchmark - and integrate automated failover tests into CI/CD pipelines to maintain reliability over time [26].
sbb-itb-535baee
Measuring Success: Governance, Metrics, and Censinet's Role
Key Metrics for Monitoring Automated Failover
When it comes to automated failover systems, two critical metrics stand out: Recovery Time Objective (RTO) and Recovery Point Objective (RPO). RTO measures how quickly systems can be restored after an incident, while RPO focuses on the maximum amount of data that can be lost without causing significant disruption [27]. Automated failover systems excel at minimizing downtime, ensuring continuous patient care even during technical issues [20].
Other essential metrics include average downtime, system uptime percentage, and the success rate of failover drills. These provide insight into how well automated processes perform under simulated conditions [27][28]. Monitoring the recovery time of Electronic Health Records (EHR) is particularly critical, as it ensures fast access to patient information when needed most [28]. Together, these metrics form the foundation for building strong recovery strategies.
Governance Models for Failover in Healthcare
Effective automated failover relies on a well-structured governance framework. Establishing a Disaster Recovery (DR) steering committee - with members from IT, compliance, operations, and clinical teams - can ensure oversight of testing schedules, policy updates, and risk assessments [20]. This collaborative approach helps align failover strategies with regulations like HIPAA and HITRUST while integrating seamlessly into clinical workflows [20].
However, there's room for improvement. Roughly one-third of healthcare organizations still test disaster recovery plans only once a year or after an incident, leaving them vulnerable to unexpected challenges [28]. Regular scenario-based recovery drills, involving all relevant stakeholders, are a proactive way to identify and fix gaps in processes, communication, and training [27][28]. Such governance ensures that automated failover systems remain reliable and contribute to broader healthcare resilience goals.
How Censinet Supports Resilience and Risk Management
Censinet RiskOps™ enhances these efforts by centralizing risk management and enabling continuous governance across healthcare IT systems. The platform integrates cybersecurity and operational risk management, automates assessments, and ensures readiness for audits.
Censinet AI™ takes this a step further by streamlining risk assessments. It summarizes evidence efficiently and routes critical findings to the right teams, much like an air traffic control system directing attention where it’s needed most.
The platform’s command center provides real-time visibility into risks impacting patient data, clinical applications, and medical devices. By presenting aggregated risk data in an easy-to-read dashboard, Censinet RiskOps™ allows healthcare organizations to define clear KPIs, measure the success of their risk management strategies, and evaluate their return on investment [29]. This comprehensive approach bolsters both operational resilience and governance, ensuring organizations are prepared for whatever challenges come their way.
Conclusion
The insights shared above highlight how automated failover systems are reshaping healthcare IT by moving it from reactive problem-solving to proactive continuity planning. In healthcare, the difference between six hours of downtime and just six minutes isn't just about convenience - it directly impacts patient care, regulatory compliance, and operational stability during system failures [3].
By ensuring real-time synchronization and encrypted key management, automated failover systems provide uninterrupted access to Protected Health Information (PHI). This prevents data loss and supports seamless operations, keeping healthcare teams connected and workflows running smoothly - critical factors in improving patient outcomes [1][2].
"Failover systems not only ensure continuous connectivity but also help meet regulatory requirements for data availability. When primary networks fail, they provide a reliable backup." – Microspace [3]
These systems also simplify compliance with HIPAA regulations. Features like automated data integrity checks, partnerships with backup providers who sign Business Associate Agreements, and regular testing of failover and failback processes ensure that healthcare organizations maintain data security and availability [1].
Solutions like Censinet RiskOps™ take this a step further by centralizing oversight of failover readiness. With real-time insights into vulnerabilities across clinical applications, medical devices, and third-party vendors, healthcare organizations can better evaluate their resilience strategies. This integrated approach emphasizes the critical role automated failover plays in modern healthcare cybersecurity and risk management.
FAQs
How do automated failover systems enhance patient safety in healthcare?
Automated failover systems are essential in safeguarding patient safety by ensuring that critical medical systems remain operational during outages or failures. These systems keep vital medical data and applications accessible, allowing healthcare professionals to provide timely and precise care without interruptions.
By automating the failover process, the risk of medical errors caused by unavailable information or workflow disruptions is significantly reduced. They also maintain operational continuity, ensuring that crucial functions like patient monitoring and access to electronic health records (EHRs) stay active when they are most needed.
What are the key components required to set up an automated failover system in healthcare IT?
An automated failover system in healthcare IT hinges on several key elements to keep operations running smoothly when disruptions occur. Among these are redundant backup systems, which step in immediately if a primary system fails, and real-time monitoring tools that can quickly identify and flag issues. Additionally, automated switching mechanisms ensure that operations are redirected seamlessly, avoiding the need for manual intervention.
Other crucial components include data synchronization protocols to uphold data accuracy, secure encryption key management to safeguard sensitive patient and operational information, and failover testing processes to verify the system's reliability under stress. To further bolster resilience, incorporating diverse connectivity options like fiber optics, wireless networks, or 5G technology helps reduce the risk of prolonged downtime.
How does automated failover support HIPAA compliance in healthcare systems?
Automated failover is essential for healthcare systems to maintain HIPAA compliance, as it ensures uninterrupted access to critical systems and data. This technology protects the confidentiality, integrity, and availability of protected health information (PHI) through real-time data replication and secure recovery processes that activate automatically when needed.
By reducing downtime and minimizing the chances of human error during system outages, automated failover helps healthcare providers deliver continuous care while meeting strict data security and availability requirements. It also plays a key role in reducing risks tied to system failures, safeguarding both patient safety and the smooth operation of healthcare services.
Related Blog Posts
- Top 7 Cloud Disaster Recovery Tools for Healthcare
- The October 2025 AWS Outage: A $62,500-Per-Hour Wake-Up Call for Healthcare Organizations
- When Multi-AZ Isn't Enough: What the AWS US-EAST-1 Failure Taught Us About True Resilience
- Why Your "Highly Available" Healthcare Cloud Architecture Failed on October 20, 2025
